1、官方文档:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding/
2、链接上一篇文章:ShardingSphere学习之垂直分库
3、公共表
(1)存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
(2)在每个数据库中创建出相同结构公共表
在多个数据库都创建相同结构公共表
如图,在多个库中创建公共表(广播表)
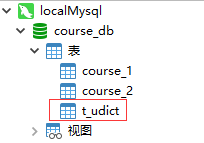
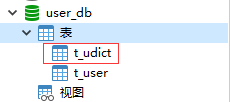
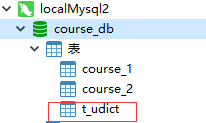
dml:
CREATE TABLE `t_udict` (
`dict_id` bigint(20) NOT NULL,
`ustatus` varchar(255) DEFAULT NULL,
`uvalue` varchar(255) DEFAULT NULL,
PRIMARY KEY (`dict_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;4、添加的部分项目截图:
5、Udict类:
package xyz.haijin.sharding.entity;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName(value = "t_udict")
public class Udict {
@TableId
private Long dictId;
private String ustatus;
private String uvalue;
}
6、UdictMapper类:
package xyz.haijin.sharding.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.springframework.stereotype.Repository;
import xyz.haijin.sharding.entity.Udict;
@Repository
public interface UdictMapper extends BaseMapper<Udict> {
}
7、配置文件:
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
# 配置数据源,给数据源起名称,多个数据源时使用逗号分隔
names: m1,m2,m0
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.141:3306/course_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.142:3306/course_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
m0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.141:3306/user_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
#默认数据源,未分片的表默认执行库
sharding:
default-data-source-name: m1
rules:
sharding:
# 分片算法配置
shardingAlgorithms:
# 这里对应shardingAlgorithmName: table-inline
table-inline:
type: INLINE
props:
sharding-count: 10
# cid为奇数时将数据存到course_2这张表中,当cid为偶数时,将数据存到course_1这种表中
algorithm-expression: course_$->{cid % 2 + 1}
# 这里对应shardingAlgorithmName: table-inline
db-inline:
type: INLINE
props:
sharding-count: 10
# user_id为奇数时将数据存到m2这张表中,当user_id为偶数时,将数据存到m1这种表中
algorithm-expression: m$->{user_id % 2 + 1}
# 这里对应shardingAlgorithmName: table-inline
user-inline:
type: INLINE
props:
algorithm-expression: t_user
# 分布式序列算法配置
keyGenerators:
# 这里对应keyGeneratorName: snowflake
snowflake:
type: SNOWFLAKE
# 分片审计算法配置
auditors:
# 这里对应 auditorNames:
# - sharding_key_required_auditor
sharding_key_required_auditor:
type: DML_SHARDING_CONDITIONS
tables:
# 表名
course:
# 库配置
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: db-inline
# 数据表配置
actualDataNodes: m$->{1..2}.course_$->{1..2}
tableStrategy:
standard:
shardingColumn: cid
shardingAlgorithmName: table-inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
t_user:
# 数据表配置
actualDataNodes: m$->{0}.t_user
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: user-inline
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
t_udict:
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
# 公共表
broadcastTables:
- t_udict
# 打开sql输出日志
props:
sql-show: true
logging:
config: classpath:logback-spring.xml
level:
org:
springframework:
boot:
autoconfigure:
logging: INFO
server:
port: 8082
mybatis-plus:
mapper-locations: classpath:xml/*.xml
# configuration:
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
注意公共表的配置
8、测试:
添加一条数据:
@Test
public void addUdictDb() {
Udict udict = new Udict();
udict.setUstatus("enable");
udict.setUvalue("已启用");
udictMapper.insert(udict);
}
删除一条数据:
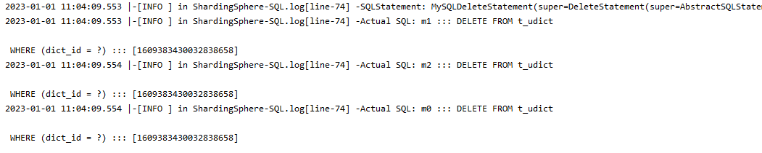
@Test
public void deleteDict() {
QueryWrapper<Udict> wrapper = new QueryWrapper<>();
//设置 userid 值
wrapper.eq("dict_id",1609383430032838658L);
udictMapper.delete(wrapper);
}
到此数据库的分库分表以及公共表操作就都已经完成了demo的展示。下一篇我们来学习一下mysql的读写分离。