1、Hbase简介:
HBase是一个分布式的、面向列的开源数据库
HBase在Hadoop之上提供了类似于Bigtable的能力
HBase不同于一般的关系数据库,它适合非结构化数据存储
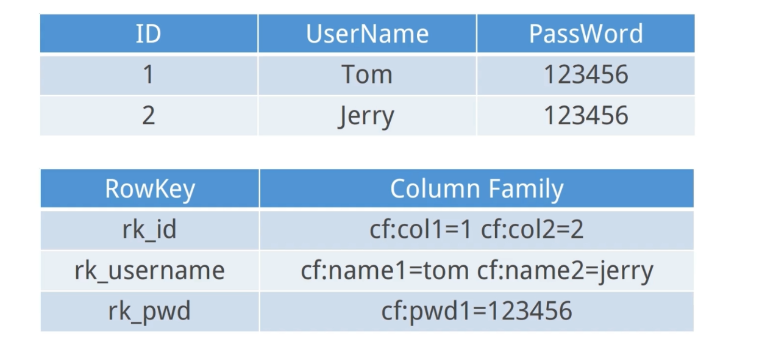
2、列式数据库与行式数据库的区别:
如图:
3、HBase在大数据生态圈中的位置
HBase是Apache基金会顶级项目
HBase基于Hadoop的核心HDFS系统进行数据存储,类似于Hive
HBase可以存储超大数据并适合用来进行大数据的实时查询
Hive:基于Hadoop的一个数据仓库工具
4、HBase 与 HDFS
HBase建立在Hadoop文件系统之上,利用了Hadoop的文件系统的容错能力
HBase提供对数据的随机实时读/写访问功能
HBase内部使用哈希表,并存储索引,可将在HDFS文件中的数据进行快速查找
5、HBase使用场景
瞬间写入量很大,常用数据库不好支撑或需要很高成本支撑的场景
数据需要长久保存,且量会持久增长到比较大的场景
HBase不适用于有join,多级索引,表关系复杂的数据模型
6、CAP 定理
一致性(所有节点在同一时间具有相同的数据)
可用性(保证每个请求不管成功或者失败都有响应,但不保证获取的数据为正确的数据)
分区容错性(系统中任意信息的丢失或失败不会影响系
丝充白勺米买
运作,系统如果不能在某一个时限内达成数据一致性,就必须在上面两个操作之间做出选择)
7、ACID定义:
原子性
—致性
隔离性
持久性
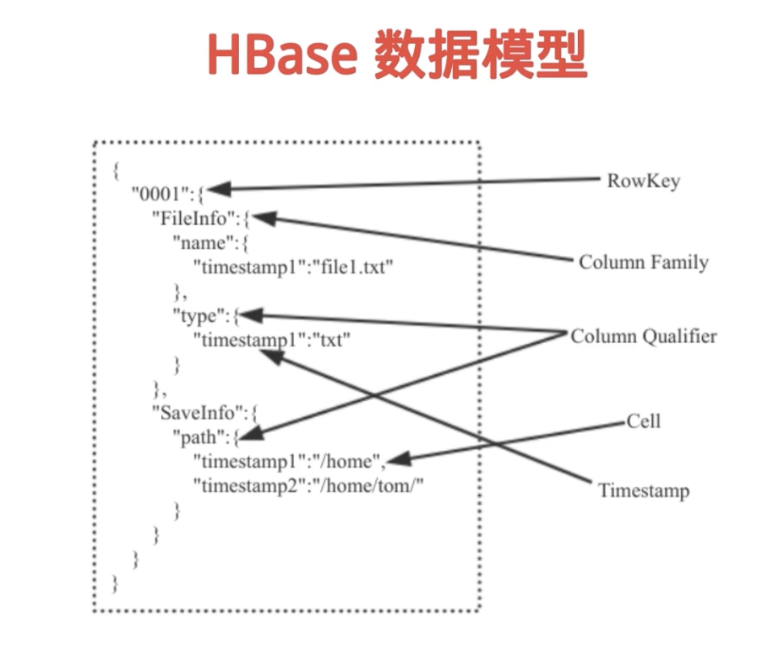
8、Hbase 中的相关概念
NameSpace:可以把NameSpace理解为RDBMS的“数据库”
Table:表名必须是能用在文件路径里的合法名字
Row:在表里面,每一行代表着一个数据对象,每一行都是以一
个行键( Row Key )来进行唯一标识的,仃捷开汉有11么心-数据类型,以二进制的字节来存储
Column: HBase的列由Column family 和Column qualifier 组成,由冒号(:)进行进行间隔。比如family:qualifier
RowKey:可以唯一标识一行记录,不可被改变
Column Family:在定义HBase表的时候需要提前设置好列族,表中所有的列都需要组织在列族里面
Column Qualifier:列族中的数据通过列标识来进行映射,可以理解为一个键值对,Column Qualifier就是Key。
Cell:每一个行键,列族和列标识共同组成一个单元
Timestamp:每个值都会有一个timestamp,作为该值特定版本的标识符
9、HBase与传统关系数据库的区别
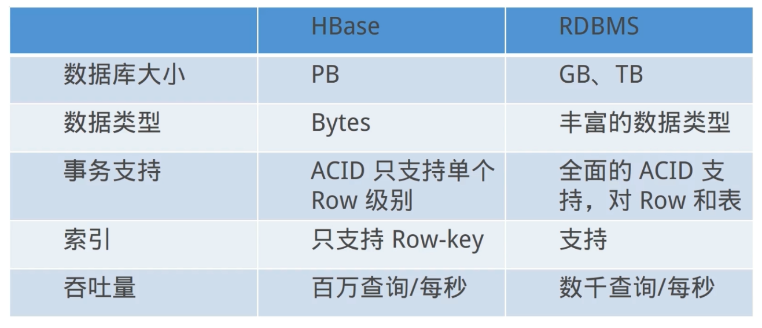
检索数据时:
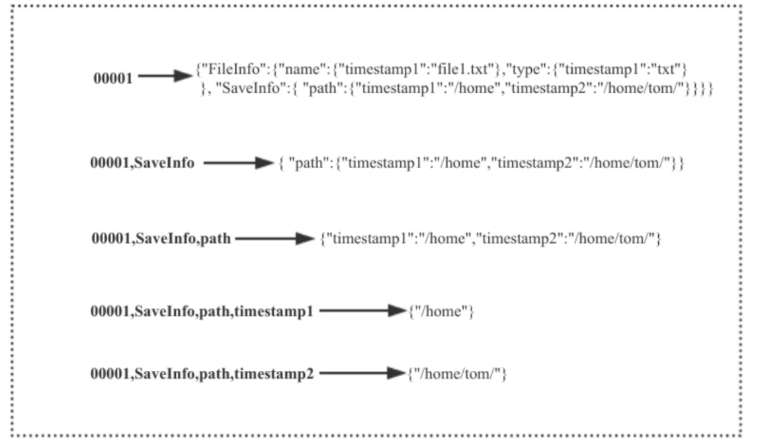
11、上图:
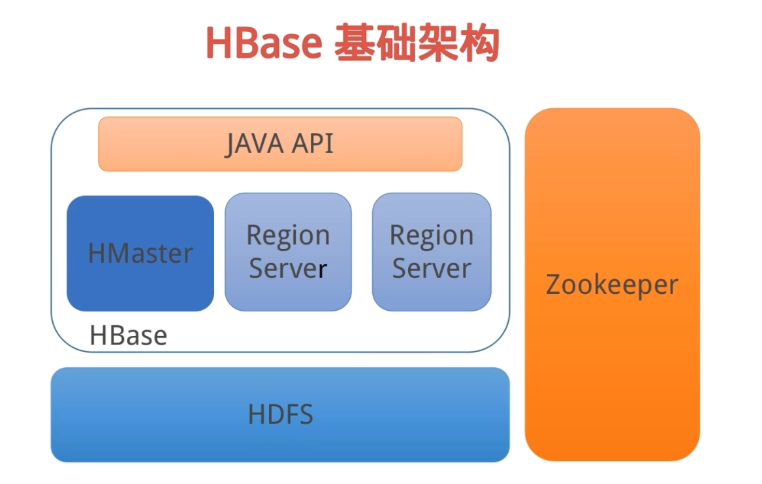
三大模块:
HMaster
RegionServer
Zookeeper
12、HMaster:
HMaster是HBase主/从集群架构中的中央节点
HMaster将region分配给RegionServer,协调RegionServer的负载并维护集群的状态
维护表和Region的元数据,不参与数据的输入/输出过程
region:是Hbase中存储的最小单元,是Hbase表格的基本单位
13、RegionServer:
维护HMaster分配给他的region,处理对这些region的io请求
负责切分正在运行过程中变的过大的region
14、Zookeeper:
Zookeeper是集群的协调器
HMaster启动将系统表加载到Zookeeper
提供HBase RegionServer状态信息