0、连接上一篇文章 mysql学习之常见的SQL查询
1、案例一
列出自己的掌门比自己年龄小的人员
select e1.name empname,e1.age empage,e2.name ceoname,e2.age ceoage
from t_emp e1 inner join t_dept d on e1.deptid=d.id
inner join t_emp e2 on d.ceo=e2.id
where e1.age>e2.age;

更换为大表,进行分析:
explain select e1.name empname,e1.age empage,e2.name ceoname,e2.age ceoage from emp e1 inner join dept d on
e1.deptid=d.id
inner join emp e2 on d.ceo=e2.id
where e1.age>e2.age;

两次 inner join 的被驱动表都已经用上了索引
2、案例二
列出所有年龄低于自己门派平均年龄的人员
思路: 先取门派的平均年龄,再跟自己的年龄做对比!
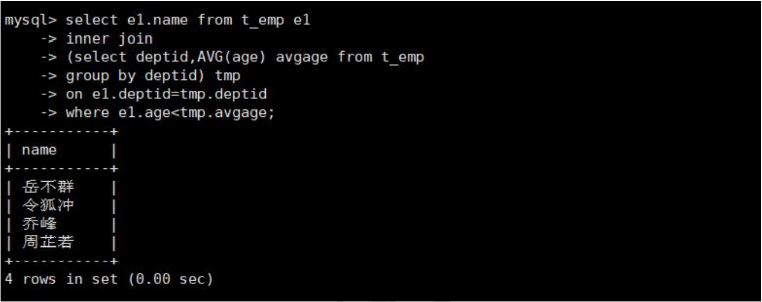
select e1.name from t_emp e1
inner join
(select deptid,AVG(age) avgage from t_emp
group by deptid) tmp
on e1.deptid=tmp.deptid
where e1.age < tmp.avgage;
更换为大表:
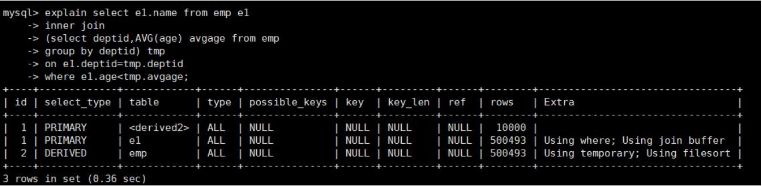
explain select e1.name from emp e1
inner join
(select deptid,AVG(age) avgage from emp
group by deptid) tmp
on e1.deptid=tmp.deptid
where e1.age<tmp.avgage
在没有索引的前提下:
如何优化:
①首先在子查询中,需要根据 deptid 做 groupby 操作,因此,需要在 deptid 上面建立索引;
②因为是 inner join,因此会自动将小表作为驱动表,也就是说,分组后的 tmp 是驱动表,而 e1 是被驱动表;
③而在 e1 中,需要查询 deptid 和 age 两个字段,因此这两个字段也需要建立索引
结果:创建 deptid 和 age 的符合索引: create index idx_deptid_age on emp(deptid,age);

3、案例三
列出至少有 2 个年龄大于 40 岁的成员的门派
思路: 先查询大于 40 岁的成员,然后按照门派分组,然后再判断至少有 2 个的门派
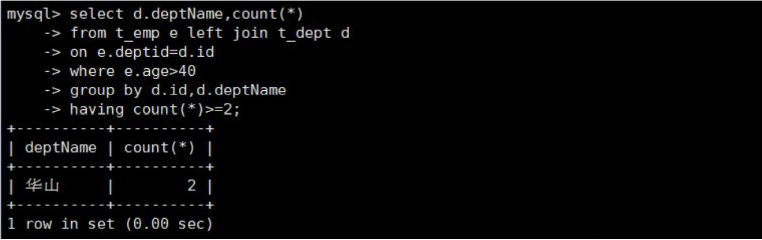
select d.deptName,count(*)
from t_emp e inner join t_dept d
on e.deptid=d.id
where e.age>40
group by d.id,d.deptName
having count(*)>=2
大表优化:
explain select d.deptName,count(*)
from emp e inner join dept d
on e.deptid=d.id
where e.age>40
group by d.id,d.deptName
having count(*)>=2;

优化:
①两表关联,我们可以考虑将小表作为驱动表。
②group by 的字段 id,deptName 还可以建立索引: create index idx_id_deptName on dept(id,deptName);
③被驱动表的 deptid 作为关联字段,可以建立索引:create index idx_deptid on emp(deptid);
create index idx_id_deptname on dept(id,deptName);

4、案例四
至少有 2 位非掌门人成员的门派
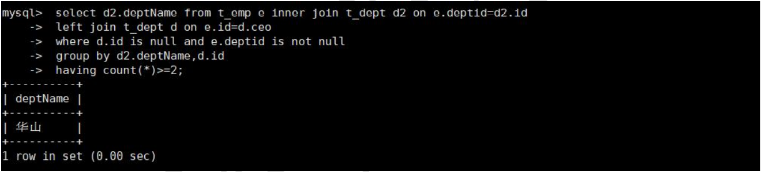
select d2.deptName from t_emp e inner join t_dept d2 on e.deptid=d2.id
left join t_dept d on e.id=d.ceo
where d.id is null and e.deptid is not null
group by d2.deptName,d2.id
having count(*)>=2;
切换大表:
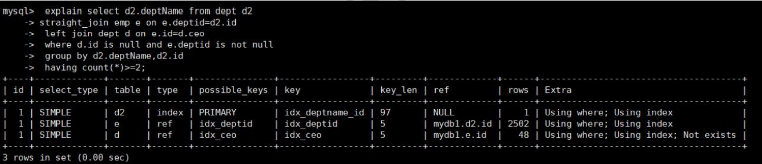
explain select d2.deptName from emp e inner join dept d2 on e.deptid=d2.id
left join dept d on e.id=d.ceo
where d.id is null and e.deptid is not null
group by d2.deptName,d2.id
having count(*)>=2;
没有索引的情况下:

优化分析: 三个表关联,然后做 group by 分组!
①group by 的字段,可以加上索引:create index idx_deptname_id on dept(deptName,id);
②可以将部门表作为驱动表
③第一次 join 时,e 表作为被驱动表,可以将 deptid 设置索引:create index idx_deptid on emp(deptid);
④最有一次 join 中,使用了 dept 表作为被驱动表,查询 ceo 字段,因此可以在 ceo 上面建立索引
create index idx_ceo on dept(ceo);
5、案例五
列出全部人员,并增加一列备注“是否为掌门”,如果是掌门人显示是,不是掌门人显示否
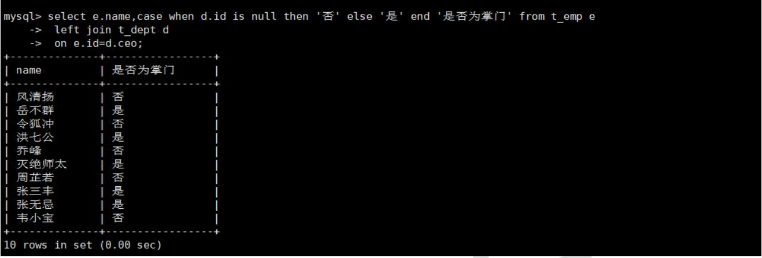
select e.name,case when d.id is null then '否' else '是' end '是否为掌门' from t_emp e
left join t_dept d
on e.id=d.ceo;
大表关联:
explain select e.name,case when d.id is null then '否' else '是' end '是否为掌门' from emp e
left join dept d
on e.id=d.ceo;
优化:在 d 表的 ceo 字段建立索引即可!
6、案例六
列出全部门派,并增加一列备注“老鸟 or 菜鸟”,若门派的平均值年龄>40 显示“老鸟”,否则显示“菜鸟”
思路: 先从 emp 表求出,各门派的平均年龄,分组,然后在关联 dept 表,使用 if 函数进行判断
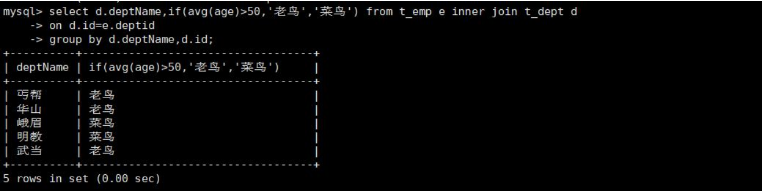
select d.deptName,if(avg(age)>40,'老鸟','菜鸟') from t_emp e inner join t_dept d
on d.id=e.deptid
group by d.deptName,d.id
切换大表:
explain select d.deptName,if(avg(age)>40,'老鸟','菜鸟') from dept d inner join emp e
on d.id=e.deptid
group by d.deptName,d.id

优化:
①使用 dept 作为驱动表
②在 dept 上建立 deptName 和 id 的索引:create index idx_deptName_id on dept(deptName,id);
③在 emp 上建立 deptid 字段的索引: create index index_deptid on emp(deptid);

7、案例七
显示每个门派年龄最大的人
思路:先查询 emp 表,求出每个门派年龄最大的人,并按照 deptid 分组;然后再次关联 emp表,关联其他的信息!
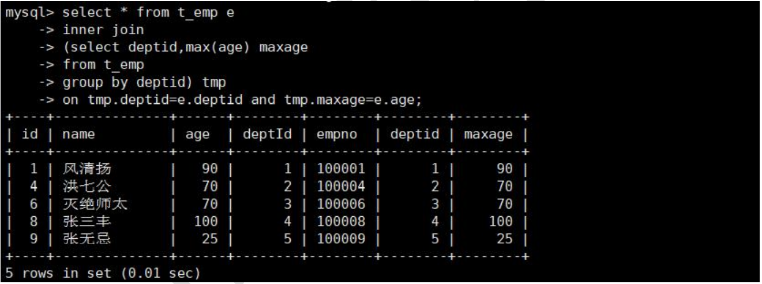
select * from t_emp e
inner join
(select deptid,max(age) maxage
from t_emp
group by deptid) tmp
on tmp.deptid=e.deptid and tmp.maxage=e.age;
大表优化:
explain select * from emp e
inner join
(select deptid,max(age) maxage
from emp
group by deptid) tmp
on tmp.deptid=e.deptid and tmp.maxage=e.age;
优化前:

优化思路:
①子查询中,emp 表根据 deptid 进行分组,因此可以建立 deptid 字段的索引;
②inner join 查询中,关联了 age 和 deptid,因此可以在 deptid,age 字段建立索引
create index idx_deptid_age on emp(deptid,age);
