0、链接上一篇文章:Hadoop3.x学习之配置历史服务器
1、在hadoop102(haijin)中:/opt/module/hadoop-3.1.3
bin/hadoop fs
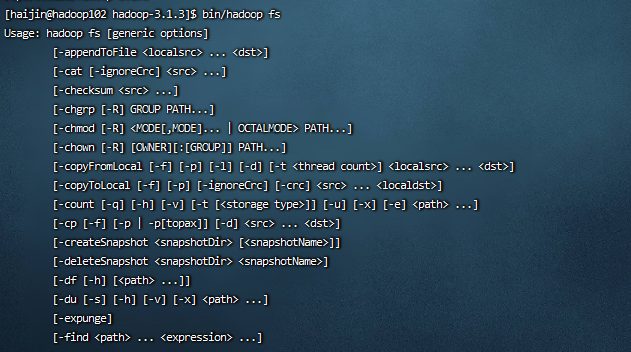
查看hadoop帮助
2、常用命令
cd /home/haijin/bin 进入到之前编写的脚本中
执行jpshall查看集群的情况
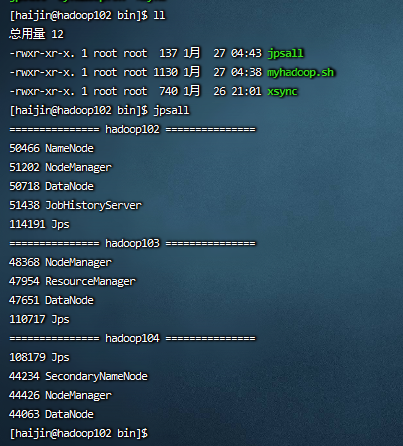
1)启动Hadoop集群(方便后续的测试)
hadoop102:
cd /opt/module/hadoop-3.1.3/sbin
start-dfs.sh
hadoop103:
cd /opt/module/hadoop-3.1.3/sbin
start-yarn.sh
2)-help:输出这个命令参数
hadoop102:
hadoop fs -help rm
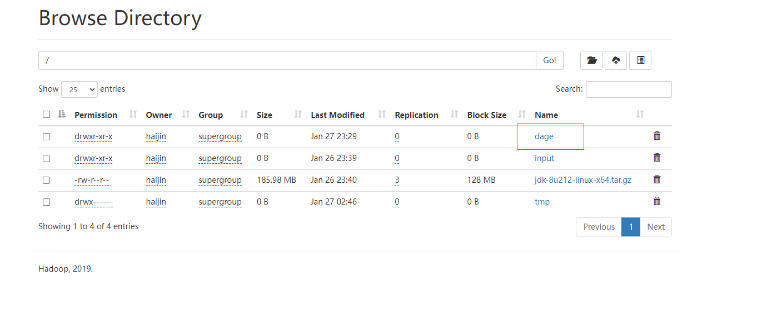
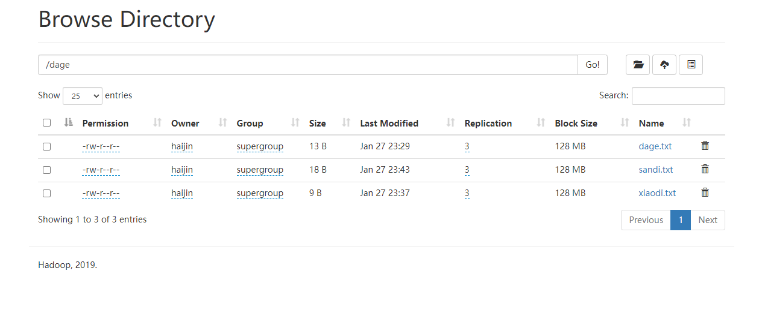
3)创建/dage文件夹
hadoop102:
hadoop fs -mkdir /dage
查看相关信息:http://hadoop102:9870/explorer.html#/
3、上传
1)-moveFromLocal:从本地剪切粘贴到HDFS
hadoop102:
cd /opt/module/hadoop-3.1.3
vim dage.txt 编辑一个文件输入一些信息
hadoop fs -moveFromLocal ./dage.txt /dage
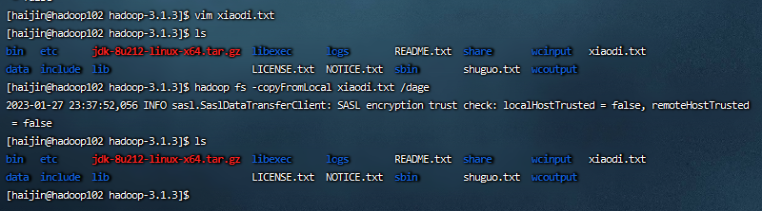
2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
vim xiaodi.txt 编辑一个文件输入一些信息
hadoop fs -copyFromLocal xiaodi.txt /dage
3)-put:等同于copyFromLocal,生产环境更习惯用put
vim sandi.txt 编辑一个文件输入一些信息
hadoop fs -put ./sandi.txt /dage
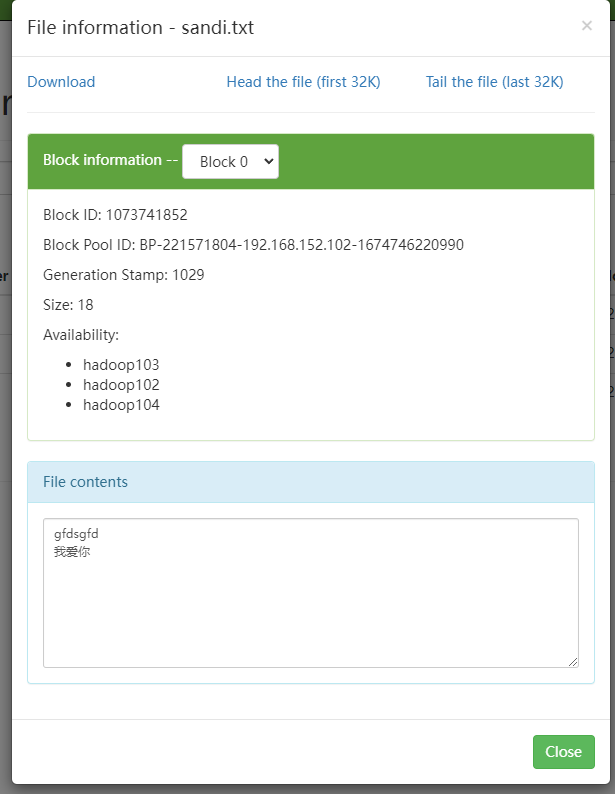
4)-appendToFile:追加一个文件到已经存在的文件末尾
vim woaini.txt 编辑一个文件输入一些信息
hadoop fs -appendToFile woaini.txt /dage/sandi.txt
4、下载
1)-copyToLocal:从HDFS拷贝到本地
hadoop102:
cd /opt/module/hadoop-3.1.3
hadoop fs -copyToLocal /dage/dage.txt ./
2)-get:等同于copyToLocal,生产环境更习惯用get
hadoop fs -get /dage/dage.txt ./dage1.txt

5、HDFS直接操作
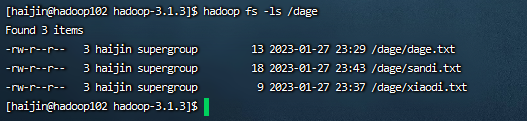
1)-ls: 显示目录信息
hadoop fs -ls /dage
2)-cat:显示文件内容
hadoop fs -cat /dage/dage.txt

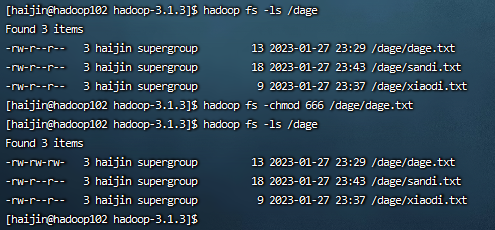
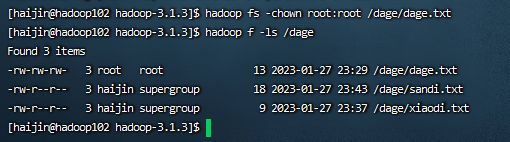
3)-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /dage/dage.txt
hadoop fs -chown haijin:haijin /dage/dage.txt
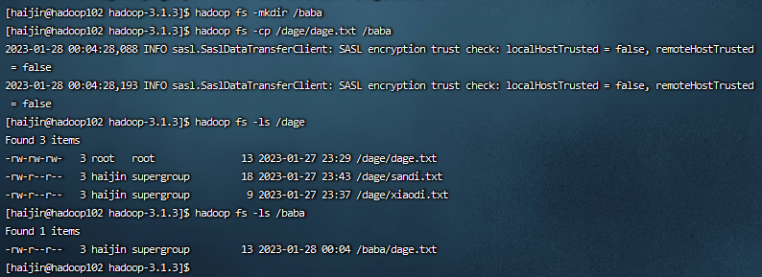
4)-mkdir:创建路径
hadoop fs -mkdir /baba
5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
hadoop fs -cp /dage/dage.txt /baba
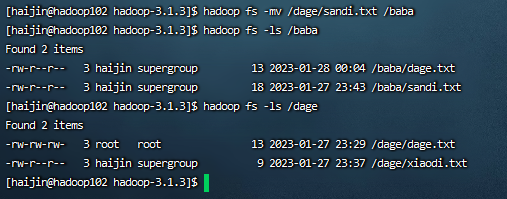
6)-mv:在HDFS目录中移动文件
hadoop fs -mv /dage/sandi.txt /baba
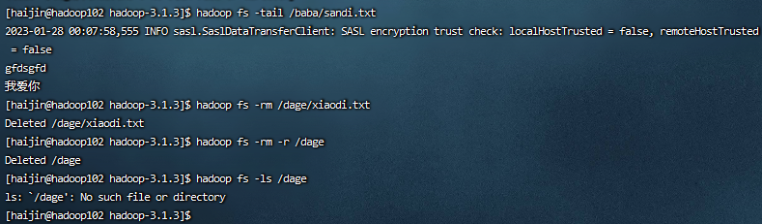
7)-tail:显示一个文件的末尾1kb的数据
hadoop fs -tail /dage/sandi.txt
8)-rm:删除文件或文件夹
hadoop fs -rm /dage/xiaodi.txt
9)-rm -r:递归删除目录及目录里面内容
10)-du统计文件夹的大小信息
hadoop fs -du -s -h /jinguo
hadoop fs -du -h /jinguo
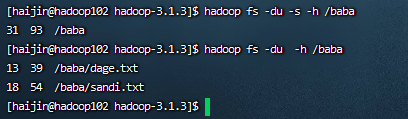
说明:31表示文件大小;93表示31*3个副本;/baba表示查看的目录
11)-setrep:设置HDFS中文件的副本数量
hadoop fs -setrep 10 /baba/dage.txt
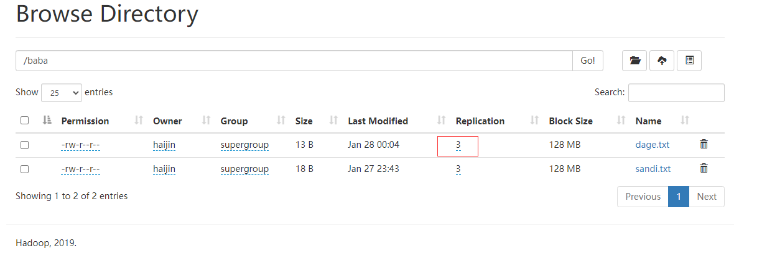
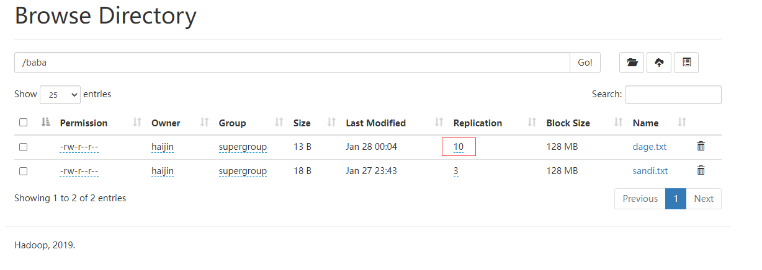
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。