1、选择Hadoop version为2.7.3的版本并下载安装包
https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/
2、安装jdk
将jdk上传到/usr/local/java目录下(没有就创建一个)
vim /etc/profile
放到文件最后:
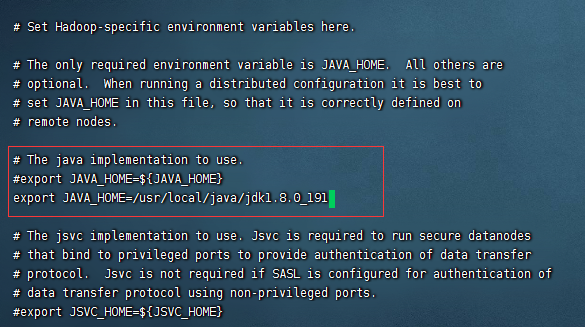
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
重新加载配置文件,输入:source /etc/profile
3、下载Hbase 1.2.4
https://archive.apache.org/dist/hbase/1.2.4/
4、配置免密登录
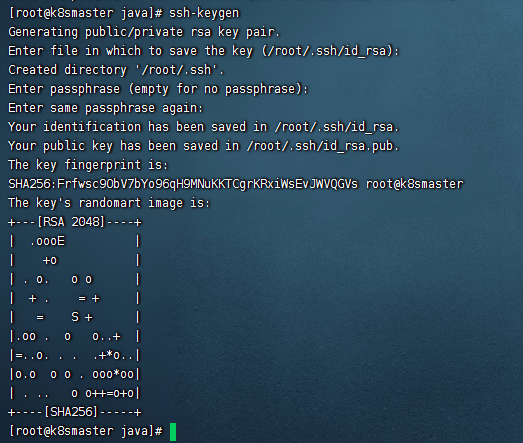
输入:ssh-keygen
如图:
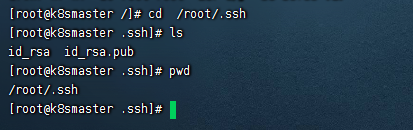
这是我们发现在/root/.ssh目录下有两个文件,如图:
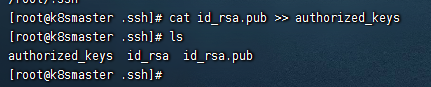
配置公钥:cat id_rsa.pub >> authorized_keys
如图:
修改权限:chmod 600 authorized_keys
如图:
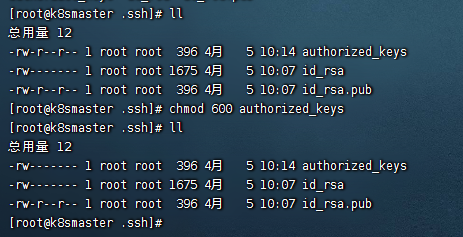
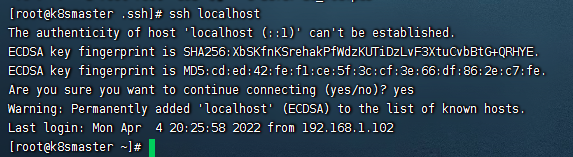
这样我们的免密登录就配置好了,如图:
5、将Hadoop和Hbase上传到/usr/local/hadoop目录下,如图:

6、进入hadoop-2.7.3/etc/hadoop目录,修改相关配置
1):修改vi hadoop-env.sh相关配置:
2):修改vi hdfs-site.xml 相关配置:
输入如下配置:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/dfs/data</value>
</property>
如图:
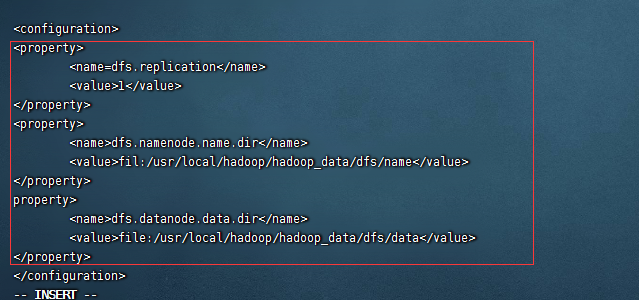
说明:第一个配置表示分片的数量,第二个配置和第三个配置表示节点的名称和数据
配置好以后要在对应的目录下创建相关的文件目录
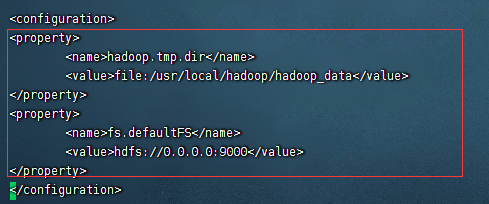
3):修改vi core-site.xml 相关配置:
输入如下配置:
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hadoop_data</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
如图:
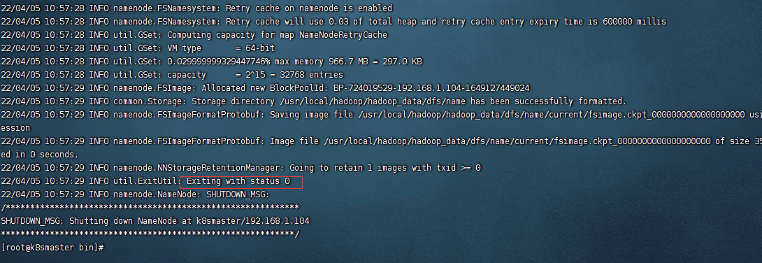
7、启动,进入hadoop的bin的目录下执行:./hdfs namenode -format
如图表示成功:
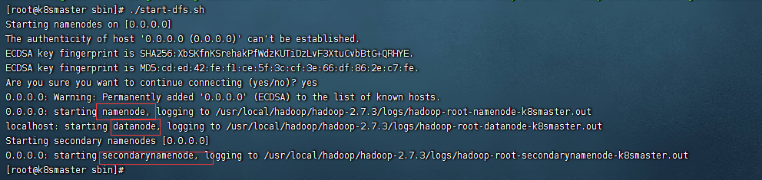
然后我们进入sbin目录下执行:./start-dfs.sh
如图:
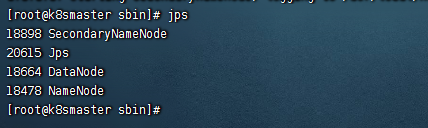
然后我们看到了这几个进程:namenode、datanode、secondarnamenode
我们可以使用jps看一下,这几个集群,如图:
然后我们进入bin目录下,执行./hdfs dfs -ls / 查看相关目录,发现什么都没有,如图:
执行:./hdfs dfs -mkdir /test 后再次执行./hdfs dfs -ls / 如图:
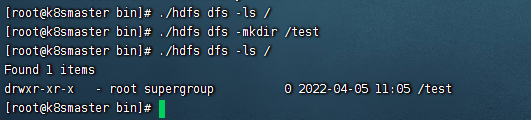
这说明我们的hadoop伪分布式集群已经可以使用了