主要内容:
1、Lambda 表达式
2、函数式接口
3、方法引用与构造器引用
4、 Stream API
5、 接口中的默认方法与静态方法
6、 新时间日期 API
7、其他新特性
Java 8新特性简介
速度更快
代码更少(增加了新的语法 Lambda 表达式)
强大的 Stream API
便于并行
最大化减少空指针异常 Optional
1-Lambda表达式
为什么使用 Lambda 表达式
Lambda 是一个匿名函数,我们可以把 Lambda
表达式理解为是一段可以传递的代码(将代码
像数据一样进行传递)。可以写出更简洁、更
灵活的代码。作为一种更紧凑的代码风格,使
Java的语言表达能力得到了提升。
Lambda 表达式
从匿名类到 Lambda 的转换

Lambda 表达式

Lambda 表达式语法
Lambda 表达式在Java 语言中引入了一个新的语法元
素和操作符。这个操作符为 “->” , 该操作符被称
为 Lambda 操作符或剪头操作符。它将 Lambda 分为
两个部分:
左侧:指定了 Lambda 表达式需要的所有参数
右侧:指定了 Lambda 体,即 Lambda 表达式要执行
的功能。
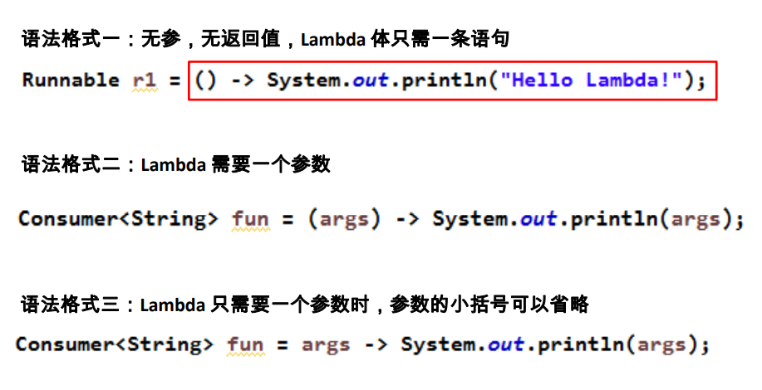
Lambda 表达式语法
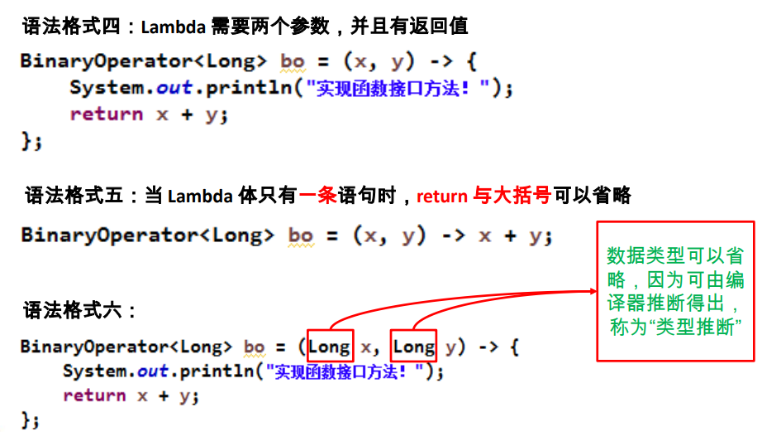
类型推断
上述 Lambda 表达式中的参数类型都是由编译器推断
得出的。Lambda 表达式中无需指定类型,程序依然可
以编译,这是因为 javac 根据程序的上下文,在后台
推断出了参数的类型。Lambda 表达式的类型依赖于上
下文环境,是由编译器推断出来的。这就是所谓的
“类型推断”
2-函数式接口
什么是函数式接口
只包含一个抽象方法的接口,称为函数式接口。
你可以通过 Lambda 表达式来创建该接口的对象。(若 Lambda
表达式抛出一个受检异常,那么该异常需要在目标接口的抽象方
法上进行声明)。
我们可以在任意函数式接口上使用 @FunctionalInterface 注解,
这样做可以检查它是否是一个函数式接口,同时 javadoc 也会包
含一条声明,说明这个接口是一个函数式接口。
自定义函数式接口

作为参数传递 Lambda 表达式
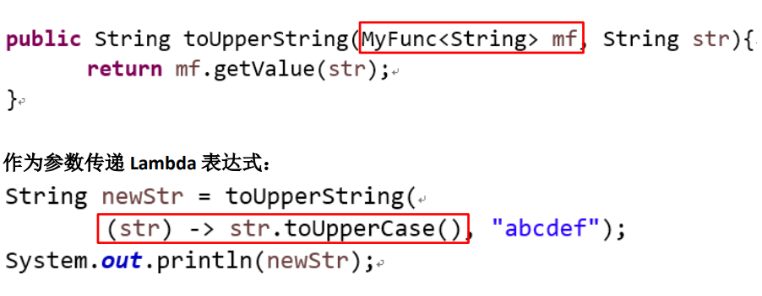
作为参数传递 Lambda 表达式:为了将 Lambda 表达式作为参数传递,接
收Lambda 表达式的参数类型必须是与该 Lambda 表达式兼容的函数式接口
的类型。
Java 内置四大核心函数式接口
| 函数式接口 | 参数类型 | 返回类型 | 用途 |
| Consumer 消费型接口 | T | void | 对类型为T的对象应用操 作,包含方法: void accept(T t) |
| Supplier 供给型接口 | 无 | T | 返回类型为T的对象,包 含方法:T get(); |
| Function<T, R> 函数型接口 |
T | R | 对类型为T的对象应用操 作,并返回结果。结果 是R类型的对象。包含方 法:R apply(T t); |
| Predicate 断定型接口 | T | boolean | 确定类型为T的对象是否 满足某约束,并返回 boolean 值。包含方法 boolean test(T t); |
其他接口
| 函数式接口 | 参数类型 | 返回类型 | 用途 |
| BiFunction<T, U, R> | T, U | R | 对类型为 T, U 参数应用 操作,返回 R 类型的结 果。包含方法为 R apply(T t, U u); |
| UnaryOperator (Function子接口) | T | T | 对类型为T的对象进行一 元运算,并返回T类型的 结果。包含方法为 T apply(T t); |
| BinaryOperator (BiFunction 子接口) | T, T | T | 对类型为T的对象进行二 元运算,并返回T类型的 结果。包含方法为 T apply(T t1, T t2); |
| BiConsumer<T, U> | T, U | void | 对类型为T, U 参数应用 操作。包含方法为 void accept(T t, U u) |
| ToIntFunction ToLongFunction ToDoubleFunction | T | int long double |
分 别 计 算 int 、 long 、 double、值的函数 |
| IntFunction LongFunction DoubleFunction | int long double |
R | 参数分别为int、long、 double 类型的函数 |
3-方法引用与构造器引用
方法引用
当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!
(实现抽象方法的参数列表,必须与方法引用方法的参数列表保持一致!)
方法引用:使用操作符 “::” 将方法名和对象或类的名字分隔开来。
如下三种主要使用情况:
对象::实例方法
类::静态方法
类::实例方法
方法引用

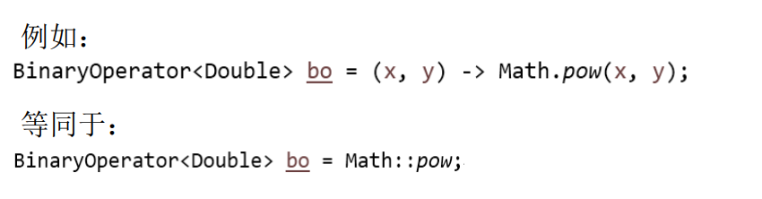
方法引用

注意:当需要引用方法的第一个参数是调用对象,并且第二个参数是需要引
用方法的第二个参数(或无参数)时:ClassName::methodName
构造器引用
格式: ClassName::new
与函数式接口相结合,自动与函数式接口中方法兼容。
可以把构造器引用赋值给定义的方法,与构造器参数
列表要与接口中抽象方法的参数列表一致!

数组引用
格式: type[] :: new

4-强大的 Stream API
了解 Stream
Java8中有两大最为重要的改变。第一个是 Lambda 表达式;另外一
个则是 Stream API(java.util.stream.*)。
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对
集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。
使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数
据库查询。也可以使用 Stream API 来并行执行操作。简而言之,
Stream API 提供了一种高效且易于使用的处理数据的方式。
什么是 Stream
流(Stream) 到底是什么呢?
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
“集合讲的是数据,流讲的是计算!”
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
Stream 的操作三个步骤
创建 Stream
一个数据源(如:集合、数组),获取一个流
中间操作
一个中间操作链,对数据源的数据进行处理
终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果

创建 Stream
Java8 中的 Collection 接口被扩展,提供了
两个获取流的方法:
default Stream stream() : 返回一个顺序流
default Stream parallelStream() : 返回一个并行流
由数组创建流
Java8 中的 Arrays 的静态方法 stream() 可
以获取数组流:
static Stream stream(T[] array): 返回一个流
重载形式,能够处理对应基本类型的数组:
public static IntStream stream(int[] array)
public static LongStream stream(long[] array)
public static DoubleStream stream(double[] array)
由值创建流
可以使用静态方法 Stream.of(), 通过显示值
创建一个流。它可以接收任意数量的参数。
public static Stream of(T... values) : 返回一个流
由函数创建流:创建无限流
可以使用静态方法 Stream.iterate() 和
Stream.generate(), 创建无限流。
迭代 public static Stream iterate(final T seed, final UnaryOperator f)
生成 public static Stream generate(Supplier s) :
Stream 的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水
线上触发终止操作,否则中间操作不会执行任何的处理!
而在终止操作时一次性全部处理,称为“惰性求值”。
筛选与切片
| 方 法 | 描 述 |
| filter(Predicate p) | 接收 Lambda , 从流中排除某些元素。 |
| distinct() | 筛选,通过流所生成元素的 hashCode() 和 equals() 去 除重复元素 |
| limit(long maxSize) | 截断流,使其元素不超过给定数量。 |
| skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素 不足 n 个,则返回一个空流。与 limit(n) 互补 |
Stream 的中间操作
映射
| 方 法 | 描 述 |
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元 素上,并将其映射成一个新的元素。 |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元 素上,产生一个新的 DoubleStream。 |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元 素上,产生一个新的 IntStream。 |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元 素上,产生一个新的 LongStream。 |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另 一个流,然后把所有流连接成一个流 |
| sorted() | 产生一个新流,其中按自然顺序排序 |
| sorted(Comparator comp) | 产生一个新流,其中按比较器顺序排序 |
Stream 的终止操作
终端操作会从流的流水线生成结果。其结果可以是任何不是流的
值,例如:List、Integer,甚至是 void 。
查找与匹配
| 方 法 | 描 述 |
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素 |
| count() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 内部迭代(使用 Collection 接口需要用户去做迭 代,称为外部迭代。相反,Stream API 使用内部 迭代——它帮你把迭代做了) |
归约
| reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。 返回 T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。 返回 Optional |
备注:map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它
来进行网络搜索而出名。
Stream 的终止操作
收集
| 方 法 | 描 述 |
| collect(Collector c) | 将流转换为其他形式。接收一个 Collector接口的 实现,用于给Stream中元素做汇总的方法 |
Collector 接口中方法的实现决定了如何对流执行收集操作(如收
集到 List、Set、Map)。但是 Collectors 实用类提供了很多静态
方法,可以方便地创建常见收集器实例,具体方法与实例如下表:
| 方法 | 返回类型 | 作用 |
| toList | List<T> | 把流中元素收集到List |
| List emps= list.stream().collect(Collectors.toList()); | ||
| toSet | Set<T> | 把流中元素收集到Set |
| Set emps= list.stream().collect(Collectors.toSet()); | ||
| toCollection | Collection<T> | 把流中元素收集到创建的集合 |
| Collectionemps=list.stream().collect(Collectors.toCollection(ArrayList::new)); | ||
| counting | Long | 计算流中元素的个数 |
| long count = list.stream().collect(Collectors.counting()); | ||
| summingInt | Integer | 对流中元素的整数属性求和 |
| inttotal=list.stream().collect(Collectors.summingInt(Employee::getSalary)); | ||
| averagingInt | Double | 计算流中元素Integer属性的平均 值 |
| doubleavg= list.stream().collect(Collectors.averagingInt(Employee::getSalary)); | ||
| summarizingInt | IntSummaryStatistics | 收集流中Integer属性的统计值。 如:平均值 |
| IntSummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getSalary)); | ||
| joining | String | 连接流中每个字符串 |
| String str= list.stream().map(Employee::getName).collect(Collectors.joining()); | ||
| maxBy | Optional<T> | 根据比较器选择最大值 |
| Optionalmax= list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary))); | ||
| minBy | Optional<T> | 根据比较器选择最小值 |
| Optional min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary))); | ||
| reducing | 归约产生的类型 | 从一个作为累加器的初始值 开始,利用BinaryOperator与 流中元素逐个结合,从而归 约成单个值 |
| inttotal=list.stream().collect(Collectors.reducing(0, Employee::getSalar, Integer::sum)); | ||
| collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结 果转换函数 |
| inthow= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size)); | ||
| groupingBy | Map<k, list<T>> | 根据某属性值对流分组,属 性为K,结果为V |
| Map<emp.status, list<emp="">> map= list.stream() .collect(Collectors.groupingBy(Employee::getStatus));</emp.status,> | ||
| partitioningBy | Map<Boolean, List<T>> | 根据true或false进行分区 |
| Map<boolean,list>vd= list.stream().collect(Collectors.partitioningBy(Employee::getManage)); </boolean,list | ||
并行流与串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分
别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并
行操作。Stream API 可以声明性地通过 parallel() 与
sequential() 在并行流与顺序流之间进行切换。
了解 Fork/Join 框架
Fork/Join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个
小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行 join 汇总.
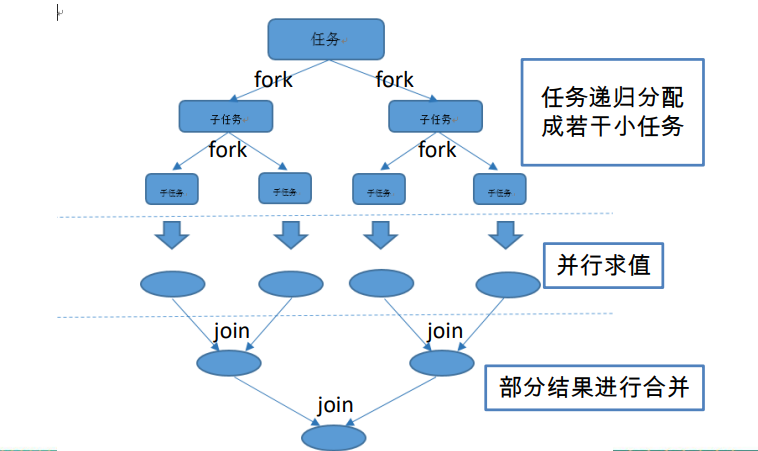
Fork/Join 框架与传统线程池的区别
采用 “工作窃取”模式(work-stealing):
当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线
程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的
处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因
无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果
某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子
问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程
的等待时间,提高了性能.
5-新时间日期 API
使用 LocalDate、LocalTime、LocalDateTime
LocalDate、LocalTime、LocalDateTime 类的实
例是不可变的对象,分别表示使用 ISO-8601日
历系统的日期、时间、日期和时间。它们提供
了简单的日期或时间,并不包含当前的时间信
息。也不包含与时区相关的信息。
注:ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示法
| 方法 | 描述 | 示例 |
| now() | 静态方法,根据当前时间创建对象 | LocalDate localDate = LocalDate.now(); LocalTime localTime = LocalTime.now(); LocalDateTime localDateTime = LocalDateTime.now(); |
| of() | 静态方法,根据指定日期/时间创建 对象 |
LocalDate localDate = LocalDate.of(2016, 10, 26); LocalTime localTime = LocalTime.of(02, 22, 56); LocalDateTime localDateTime = LocalDateTime.of(2016, 10, 26, 12, 10, 55); |
| plusDays, plusWeeks, plusMonths, plusYears |
向当前 LocalDate 对象添加几天、 几周、几个月、几年 |
|
| minusDays, minusWeeks, minusMonths, minusYears |
从当前 LocalDate 对象减去几天、 几周、几个月、几年 |
|
| plus, minus | 添加或减少一个 Duration 或 Period | |
| withDayOfMonth, withDayOfYear, withMonth, withYear |
将月份天数、年份天数、月份、年 份 修 改 为 指 定 的 值 并 返 回 新 的 LocalDate 对象 |
|
| getDayOfMonth | 获得月份天数(1-31) | |
| getDayOfYear | 获得年份天数(1-366) | |
| getDayOfWeek | 获得星期几(返回一个 DayOfWeek 枚举值) |
|
| getMonth | 获得月份, 返回一个 Month 枚举值 | |
| getMonthValue | 获得月份(1-12) | |
| getYear | 获得年份 | |
| until | 获得两个日期之间的 Period 对象, 或者指定 ChronoUnits 的数字 |
|
| isBefore, isAfter | 比较两个 LocalDate | |
| isLeapYear | 判断是否是闰年 |
Instant 时间戳
用于“时间戳”的运算。它是以Unix元年(传统
的设定为UTC时区1970年1月1日午夜时分)开始
所经历的描述进行运算
Duration 和 Period
Duration:用于计算两个“时间”间隔
Period:用于计算两个“日期”间隔
日期的操纵
TemporalAdjuster : 时间校正器。有时我们可能需要获
取例如:将日期调整到“下个周日”等操作。
TemporalAdjusters : 该类通过静态方法提供了大量的常
用 TemporalAdjuster 的实现。
例如获取下个周日:

解析与格式化
java.time.format.DateTimeFormatter 类:该类提供了三种
格式化方法:
预定义的标准格式
语言环境相关的格式
自定义的格式
时区的处理
Java8 中加入了对时区的支持,带时区的时间为分别为:
ZonedDate、ZonedTime、ZonedDateTime
其中每个时区都对应着 ID,地区ID都为 “{区域}/{城市}”的格式
例如 :Asia/Shanghai 等
ZoneId:该类中包含了所有的时区信息
getAvailableZoneIds() : 可以获取所有时区时区信息
of(id) : 用指定的时区信息获取 ZoneId 对象
与传统日期处理的转换
| 类 | To 遗留类 | From 遗留类 |
| java.time.Instant java.util.Date |
Date.from(instant) | date.toInstant() |
| java.time.Instant java.sql.Timestamp |
Timestamp.from(instant) | timestamp.toInstant() |
| java.time.ZonedDateTime java.util.GregorianCalendar |
GregorianCalendar.from(zonedDateTim e) |
cal.toZonedDateTime() |
| java.time.LocalDate java.sql.Time |
Date.valueOf(localDate) | date.toLocalDate() |
| java.time.LocalTime java.sql.Time |
Date.valueOf(localDate) | date.toLocalTime() |
| java.time.LocalDateTime java.sql.Timestamp |
Timestamp.valueOf(localDateTime) | timestamp.toLocalDateTime() |
| java.time.ZoneId java.util.TimeZone |
Timezone.getTimeZone(id) | timeZone.toZoneId() |
| java.time.format.DateTimeFormatter java.text.DateFormat |
formatter.toFormat() | 无 |
6-接口中的默认方法与静态方法
接口中的默认方法
Java 8中允许接口中包含具有具体实现的方法,该方法称为
“默认方法”,默认方法使用 default 关键字修饰。
例如:

接口中的默认方法
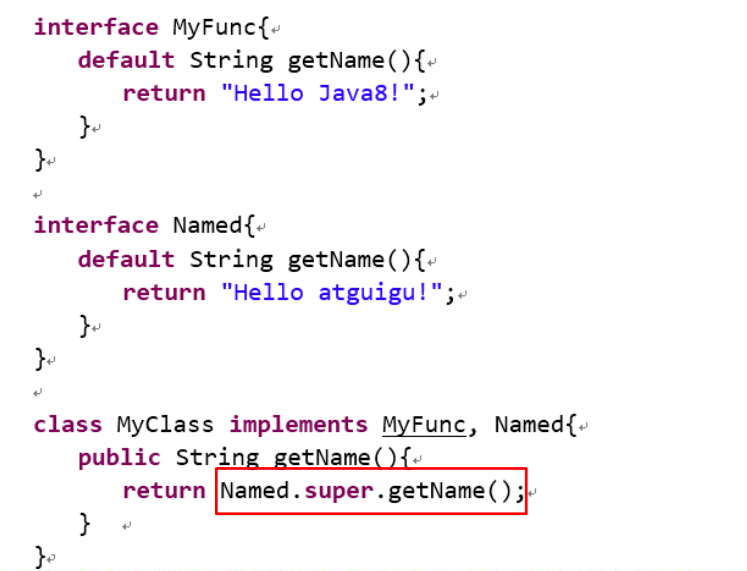
接口默认方法的”类优先”原则
若一个接口中定义了一个默认方法,而另外一个父类或接口中
又定义了一个同名的方法时
选择父类中的方法。如果一个父类提供了具体的实现,那么
接口中具有相同名称和参数的默认方法会被忽略。
接口冲突。如果一个父接口提供一个默认方法,而另一个接
口也提供了一个具有相同名称和参数列表的方法(不管方法
是否是默认方法),那么必须覆盖该方法来解决冲突
接口默认方法的”类优先”原则:
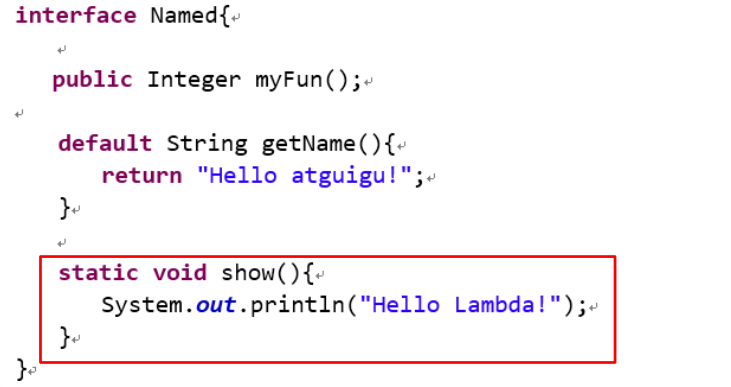
接口中的静态方法
Java8 中,接口中允许添加静态方法。
例如:
7-其他新特性
Optional 类
Optional 类(java.util.Optional) 是一个容器类,代表一个值存在或不存在, 原来用 null 表示一个值不存在,现在 Optional 可以更好的表达这个概念。并且 可以避免空指针异常。
常用方法:
Optional.of(T t) : 创建一个 Optional 实例
Optional.empty() : 创建一个空的 Optional 实例
Optional.ofNullable(T t):若 t 不为 null,创建 Optional 实例,否则创建空实例
isPresent() : 判断是否包含值
orElse(T t) : 如果调用对象包含值,返回该值,否则返回t
orElseGet(Supplier s) :如果调用对象包含值,返回该值,否则返回 s 获取的值
map(Function f): 如果有值对其处理,并返回处理后的Optional,否则返回 Optional.empty()
flatMap(Function mapper):与 map 类似,要求返回值必须是Optional
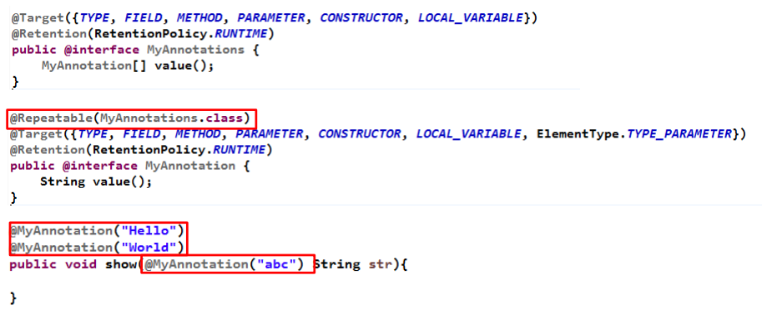
重复注解与类型注解
Java 8对注解处理提供了两点改进:可重复的注解及可用于类
型的注解。
2022-06-22
start:
end
2023-03-27:
start:
在 Java 8 中,可以使用流(Stream)和Lambda表达式来对一个对象集合进行过滤。假设我们有一个包含多个实体对象的集合,每个实体对象都有一个唯一的id属性,我们可以使用流的filter方法和Lambda表达式来过滤出指定id的实体对象。
import java.util.ArrayList;
import java.util.List;
public class Entity {
private int id;
private String name;
public Entity(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public static void main(String[] args) {
List<Entity> entityList = new ArrayList<>();
entityList.add(new Entity(1, "John"));
entityList.add(new Entity(2, "Mary"));
entityList.add(new Entity(3, "Bob"));
int targetId = 2;
Entity resultEntity = entityList.stream()
.filter(entity -> entity.getId() == targetId)
.findFirst()
.orElse(null);
if (resultEntity != null) {
System.out.println("Found entity with id " + targetId + ": " + resultEntity.getName());
} else {
System.out.println("No entity found with id " + targetId);
}
}
}end
2023-04-17 start:
通过一个key 模糊搜索id或者title,id匹配到了,放结果集的前面,title放后面,对于多个匹配的id按照id倒序排序,然后对于多个匹配的title按照tilte倒序排序
jdk8,假设你有一个 List 类型的数据集合,包含了需要进行模糊匹配的 id 和 title 字段,那么你可以使用 Java 8 的 stream() 和 sorted() 方法来完成这一需求,具体实现步骤如下:
List<Data> dataList = ... // 假设 dataList 是数据集合,其中 Data 是数据模型类,包含 id 和 title 字段
String key = ... // 假设 key 是模糊匹配的关键词
List<Data> result = dataList.stream()
.filter(data -> data.getId().contains(key) || data.getTitle().contains(key)) // 过滤出 id 或 title 包含关键词的数据
.sorted(Comparator.comparing((Data data) -> data.getId().contains(key) ? 0 : 1) // 根据 id 是否匹配关键词进行排序
.thenComparing(Comparator.comparing(Data::getId).reversed()) // 对匹配关键词的 id 进行倒序排序
.thenComparing(Comparator.comparing((Data data) -> data.getTitle().contains(key) ? 0 : 1) // 根据 title 是否匹配关键词进行排序
.thenComparing(Comparator.comparing(Data::getTitle).reversed()))) // 对匹配关键词的 title 进行倒序排序
.collect(Collectors.toList());在上述代码中,我们首先使用 stream() 方法将数据集合转化为一个流,然后使用 filter() 方法过滤出符合条件的数据,再使用 sorted() 方法进行排序,最后使用 collect() 方法将排序后的数据收集到一个列表中。
在 sorted() 方法中,我们使用 Comparator 对象来定义排序规则。首先根据 id 是否匹配关键词进行排序,如果匹配则返回 0,否则返回 1,这样就可以将匹配关键词的 id 放在前面。接着对匹配关键词的 id 进行倒序排序,这样最新的匹配项就可以排在前面。然后根据 title 是否匹配关键词进行排序,同样先返回 0 或 1,然后对匹配关键词的 title 进行倒序排序,这样匹配关键词的 title 就可以排在匹配项之后。
需要注意的是,在实际应用中,可能需要根据具体情况对排序规则进行调整。另外,上述代码中使用了 Java 8 的 lambda 表达式和方法引用来简化代码,需要确保项目的 JDK 版本兼容。
end