1、我们先看一下下厨房的网站是什么样的?
打开 https://www.xiachufang.com/
如图:
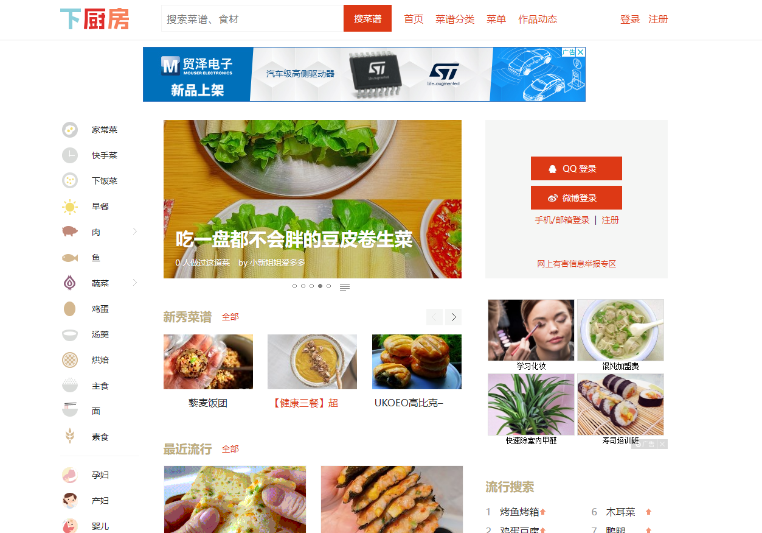
靠,把劳资看饿了。
去炒个面:

2、少废话,上代码:
首先是bs4的爬取:
import os
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import requests
r = requests.get('http://www.xiachufang.com/')
soup = BeautifulSoup(r.text)
img_list = []
for img in soup.select('img'):
if img.has_attr('data-src'):
img_list.append(img.attrs['data-src'])
else:
img_list.append(img.attrs['src'])
# 初始化下载文件目录
image_dir = os.path.join(os.curdir, 'images')
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
for img in img_list[::-1]:
o = urlparse(img)
filename = o.path[1:].split('@')[0]
filepath = os.path.join(image_dir, filename)
if not os.path.isdir(os.path.dirname(filepath)):
os.mkdir(os.path.dirname(filepath))
url = '%s://%s/%s' % (o.scheme, o.netloc, filename)
print(url)
resp = requests.get(url)
with open(filepath, 'wb') as f:
for chunk in resp.iter_content(1024):
f.write(chunk)
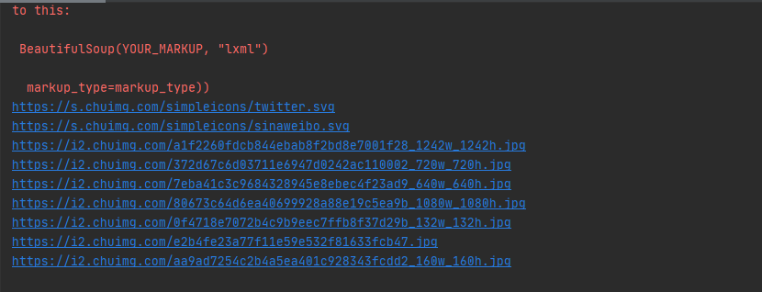
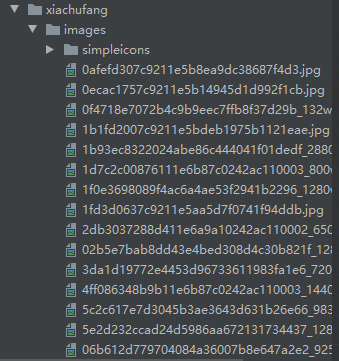
爬取的效果如下:
图片下载如图:
3、通过curl的方式去爬取,代码如下:
import re
import os
from io import BytesIO
from urllib.parse import urlparse
from pycurl import Curl
buffer = BytesIO()
c = Curl()
c.setopt(c.URL, 'http://www.xiachufang.com/')
c.setopt(c.WRITEDATA, buffer)
c.perform()
c.close()
body = buffer.getvalue()
text = body.decode('utf-8')
print(text)
img_list = re.findall(r'src=\"(http://i2\.chuimg\.com/\w+\.jpg)',
text)
# 初始化下载文件目录
image_dir = os.path.join(os.curdir, 'images')
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
for img in img_list[::-1]:
o = urlparse(img)
filename = o.path[1:]
filepath = os.path.join(image_dir, filename)
if not os.path.isdir(os.path.dirname(filepath)):
os.mkdir(os.path.dirname(filepath))
url = '%s://%s/%s' % (o.scheme, o.netloc, filename)
print(url)
with open(filepath, 'wb') as f:
c = Curl()
c.setopt(c.URL, url)
c.setopt(c.WRITEDATA, f)
c.perform()
c.close()