1、常见的 Join 查询图
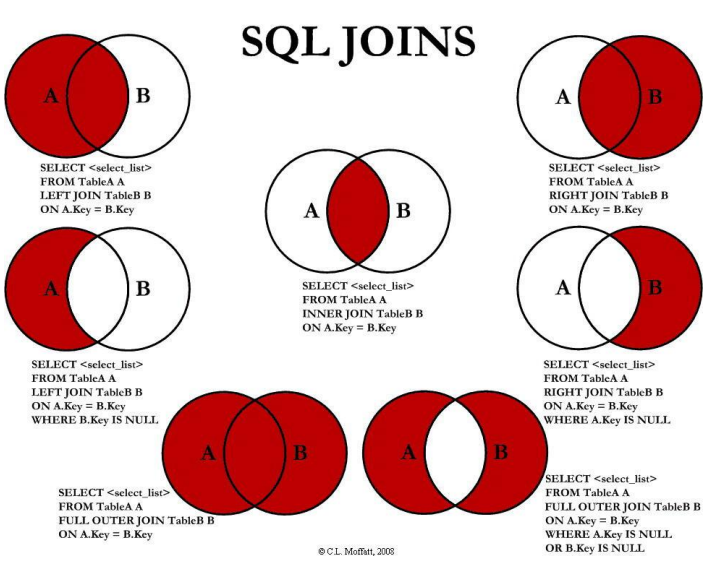
2、Join 示例
2.1 建表语句
CREATE TABLE `t_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAULT NULL, `address` VARCHAR(40) DEFAULT NULL, PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `t_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(20) DEFAULT NULL, `age` INT(3) DEFAULT NULL, `deptId` INT(11) DEFAULT NULL, empno int not null, PRIMARY KEY (`id`), KEY `idx_dept_id` (`deptId`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO t_dept(deptName,address) VALUES('华山','华山');
INSERT INTO t_dept(deptName,address) VALUES('丐帮','洛阳');
INSERT INTO t_dept(deptName,address) VALUES('峨眉','峨眉山');
INSERT INTO t_dept(deptName,address) VALUES('武当','武当山');
INSERT INTO t_dept(deptName,address) VALUES('明教','光明顶');
INSERT INTO t_dept(deptName,address) VALUES('少林','少林寺');
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('风清扬',90,1,100001);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('岳不群',50,1,100002);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('令狐冲',24,1,100003);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('洪七公',70,2,100004);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('乔峰',35,2,100005);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('灭绝师太',70,3,100006);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('周芷若',20,3,100007);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('张三丰',100,4,100008);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('张无忌',25,5,100009);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('韦小宝',18,null,100010);
2.2 案例
1.所有有门派人员的信息(要求显示门派名称)
SELECT e.`name`,d.`deptName` FROM t_emp e INNER JOIN t_dept d ON e.`deptId`=d.`id`;
2. 列出所有人员及其门派信息
SELECT e.`name`,d.`deptName` FROM t_emp e LEFT JOIN t_dept d ON e.`deptId`=d.`id`;
3. 列出所有门派
SELECT * FROM t_dept;
4. 所有无门派人士
SELECT * FROM t_emp WHERE deptId IS NUL;
5. 所有无人门派
SELECT d.* FROM t_dept d LEFT JOIN t_emp e ON d.`id`=e.`deptId` WHERE e.`deptId` IS NULL;
6. 所有人员和门派的对应关系
SELECT * FROM t_emp e LEFT JOIN t_dept d ON e.`deptId`=d.`id` UNION
SELECT * FROM t_emp e RIGHT JOIN t_dept d ON e.`deptid`=d.id;
7. 所有没有入门派的人员和没人入的门派
SELECT * FROM t_emp e LEFT JOIN t_dept d ON e.`deptId`=d.`id` WHERE e.deptId IS NULL
UNION
SELECT * FROM t_dept d LEFT JOIN t_emp e ON d.`id`=e.`deptId` WHERE e.`deptId` IS NULL;
8. 添加 CEO 字段
ALTER TABLE `t_dept` add CEO INT(11) ;
update t_dept set CEO=2 where id=1;
update t_dept set CEO=4 where id=2;
update t_dept set CEO=6 where id=3;
update t_dept set CEO=8 where id=4;
update t_dept set CEO=9 where id=5;
8.1 求各个门派对应的掌门人名称
SELECT d.deptName,e.name FROM t_dept d LEFT JOIN t_emp e ON d.ceo=e.id
8.2 求所有当上掌门人的平均年龄
SELECT AVG(e.age) FROM t_dept d LEFT JOIN t_emp e ON d.ceo=e.id
8.3 求所有人物对应的掌门名称
SELECT ed.name '人物',c.name '掌门' FROM
(SELECT e.name,d.ceo from t_emp e LEFT JOIN t_dept d on e.deptid=d.id) ed
LEFT JOIN t_emp c on ed.ceo= c.id;
SELECT e.name '人物',tmp.name '掌门' FROM t_emp e LEFT JOIN (SELECT d.id did,e.name FROM t_dept d LEFT JOIN t_emp e ON d.ceo=e.id)tmp
ON e.deptId=tmp.did;
SELECT e1.name '人物',e2.name '掌门' FROM t_emp e1
LEFT JOIN t_dept d on e1.deptid = d.id
LEFT JOIN t_emp e2 on d.ceo = e2.id;
SELECT e2.name '人物', (SELECT e1.name FROM t_emp e1 where e1.id= d.ceo) '掌门' from
t_emp e2 LEFT JOIN t_dept d on e2.deptid=d.id;
2023-04-01:
start:
1、有一个表,id,name两个字段,name重复,怎么查出来重复数据:
可以使用 SQL 语句进行查找,具体的 SQL 语句如下:
SELECT name, COUNT(*) as count
FROM table_name
GROUP BY name
HAVING count > 1;其中,table_name 是需要查询的表名,name 是需要查找重复数据的字段名。
该 SQL 语句首先按照 name 字段进行分组,然后统计每个分组内的行数,最后只保留行数大于 1 的分组,也就是有重复数据的分组。这些分组中的每个 name 值都是重复的,同时还会返回每个重复值出现的次数。
使用该 SQL 语句可以快速查询出有重复数据的行,并且可以同时得到每个重复值出现的次数。如果需要删除重复数据,可以使用 DELETE 语句结合上述查询结果进行操作。
2、再加一个字段age,怎么统计出不同年龄段的人数,比如30以下,30到40,40到50,50以上等
SELECT
CASE
WHEN age < 30 THEN '30以下'
WHEN age >= 30 AND age < 40 THEN '30到40'
WHEN age >= 40 AND age < 50 THEN '40到50'
ELSE '50以上'
END AS age_range,
COUNT(*) AS count
FROM table_name
GROUP BY age_range;其中,table_name 是需要查询的表名,age 是年龄字段名,age_range 是统计出来的年龄段,count 是每个年龄段的人数。
该 SQL 语句使用 CASE WHEN 语句将年龄字段划分为不同的年龄段,然后按照年龄段进行分组,最后统计每个分组内的行数,也就是每个年龄段的人数。
使用该 SQL 语句可以快速统计出不同年龄段的人数,根据需要可以进一步对结果进行排序、筛选等操作。
end
2023-04-17 start:
通过一个key 模糊搜索id或者title,id匹配到了,放结果集的前面,title放后面,对于多个匹配的id按照id倒序排序
SELECT * FROM table WHERE id LIKE '%key%' OR title LIKE '%key%' ORDER BY CASE WHEN id LIKE '%key%' THEN 0 ELSE 1 END, id DESCCASE WHEN id LIKE '%key%' THEN 0 ELSE 1 END 是一个SQL中的条件表达式,它的作用是判断 id 是否匹配关键词 key。
具体来说,当 id LIKE '%key%' 时,该条件表达式的值为 0;否则,表达式的值为 1。也就是说,对于每一行数据,如果 id 包含关键词 key,那么该行数据在排序时会被放在前面;否则,该行数据会被放在后面。
在本例中,我们把匹配关键词的 id 放在前面,使用了该条件表达式来实现这一目的。如果 id 包含关键词 key,那么该表达式的值为 0,该行数据将会在排序时排在前面。如果 id 不包含关键词 key,那么该表达式的值为 1,该行数据将会在排序时排在后面。
为什么 当 id LIKE '%key%' 时,该条件表达式的值为 0 数据在排序时会被放在前面?
当 id LIKE '%key%' 时,该条件表达式的值为 0,这意味着该行数据在排序时会排在前面。这是因为在 SQL 中,使用 ORDER BY 子句对查询结果进行排序时,默认是按照升序排序进行的,也就是说,值小的排在前面,值大的排在后面。
在这个例子中,我们想要把匹配关键词 key 的 id 放在前面,而不是按照升序排序。因此,我们需要使用条件表达式来控制排序的顺序。当 id LIKE '%key%' 时,该条件表达式的值为 0,相当于把匹配关键词的 id 视为一个比较小的值,因此该行数据会排在前面。当 id LIKE '%key%' 不成立时,条件表达式的值为 1,相当于把不匹配关键词的 id 视为一个比较大的值,因此该行数据会排在后面。
综上所述,使用条件表达式来控制排序的顺序,是一种比较灵活的方式,可以根据实际需求来决定如何排列数据。
如果要建立索引来保证查询的速度应该怎么建?
如果您需要保证查询的速度,可以考虑为表中的 id 和 title 字段创建索引。在建立索引时,需要考虑到以下几点:
-
索引类型:
id字段通常是主键或唯一键,因此需要创建唯一索引;title字段则不需要唯一索引,因为可能存在相同的标题。可以根据实际情况选择适当的索引类型。 -
索引顺序:由于您需要根据
id字段进行匹配和排序,因此需要将id字段放在索引的前面。例如,可以创建(id, title)的复合索引,以保证查询效率。 -
索引长度:如果
id字段的长度很长,可以考虑只对id字段的前缀进行索引,以减少索引的大小和建立索引的时间。例如,可以创建(id(10), title)的复合索引,以只索引id字段的前 10 个字符。
以下是创建索引的示例 SQL 语句:
-- 创建唯一索引
CREATE UNIQUE INDEX idx_id ON table(id);
-- 创建复合索引
CREATE INDEX idx_id_title ON table(id, title);
-- 创建只索引 id 字段前 10 个字符的复合索引
CREATE INDEX idx_id_title ON table(id(10), title);需要注意的是,索引会占用一定的存储空间,对表的更新操作(例如插入、更新和删除)也会受到一定的影响。因此,在创建索引时需要权衡索引的利弊,避免过度索引导致性能下降。
对于多个匹配的id按照id倒序排序,然后对于多个匹配的title按照tilte倒序排序
SELECT *
FROM table
WHERE id LIKE '%key%' OR title LIKE '%key%'
ORDER BY id LIKE '%key%' DESC, id DESC, title LIKE '%key%' DESC, title DESC;
在 ORDER BY 子句中,我们首先按照 id LIKE '%key%' 的值进行排序,该表达式的值为 0 或 1,因此使用 DESC 关键字可以将匹配关键词的 id 排在前面。如果有多个匹配的 id,则按照 id 的倒序排序,即最新的 id 排在前面。接着按照 title LIKE '%key%' 的值进行排序,同样使用 DESC 关键字可以将匹配关键词的 title 排在前面。最后,按照 title 的倒序排序,可以将匹配关键词的 title 放在前面。
需要注意的是,多个排序规则的优先级是从左到右依次降低的。在实际应用中需要根据具体情况进行调整。
为什么 id LIKE '%key%' 值为0或1?
当 id LIKE '%key%' 匹配成功时,它的值为 1;否则,它的值为 0。在 SQL 语句中,当使用 LIKE 关键字时,可以使用百分号(%)来表示通配符,表示可以匹配任意字符,其中 %key% 表示在 id 列中匹配包含关键词 key 的值。如果 id 列的值包含关键词 key,那么 id LIKE '%key%' 的值为 1,否则为 0。
在 SQL 语句中,LIKE 关键字通常用于模糊匹配。当需要对某个字段进行模糊查询时,可以使用 LIKE 关键字,并在查询条件中使用 % 或 _ 等通配符,来实现通用的匹配。
end