1、我们首先使用一条命令:alias myip="curl http://httpbin.org/get|grep -E ''[0:9]''|grep -v User-Agent|cut -d '"' -f4",然后使用myip进行查看,如图:

这样我们就能看到外网的ip地址了。
2、什么是wget?wget和curl类似我们一般使用wget来进行文件下载的操作。首先我进行wget的安装,命令如下:
apt install wget 如命令不能使用,使用yum -y install wget安装wget命令
wget http://httpbin.org/images/png
如图:
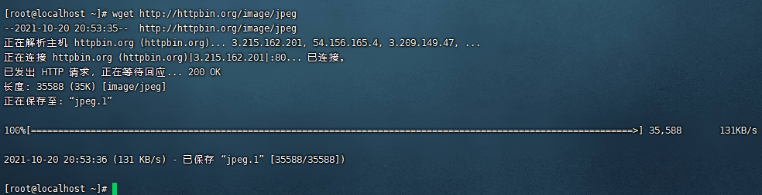
使用wget -O test.jpeg http://httpbin.org/image/jpeg 这样就能将图片下载并命名为test.jpeg。
3、我们发现其实wget和curl的命令是类似的,我们总结一下相关常用的命令参数,如下:
-O 以指定文件名保存下载的文件 wget -O test.png http://httpbin.org/image/png
--limit-rate 以指定的速度下载目标文件 --limit-rate=200k
-c 断点续传
-b 后台下载
-U 设置User-Agent
--mirror 镜像某个目标网站
-p 下载页面中的所有相关资源
-r 递归下载所有网页中所有的链接
4、我们可以根据上述的这些命令来完成某一些事情,如:
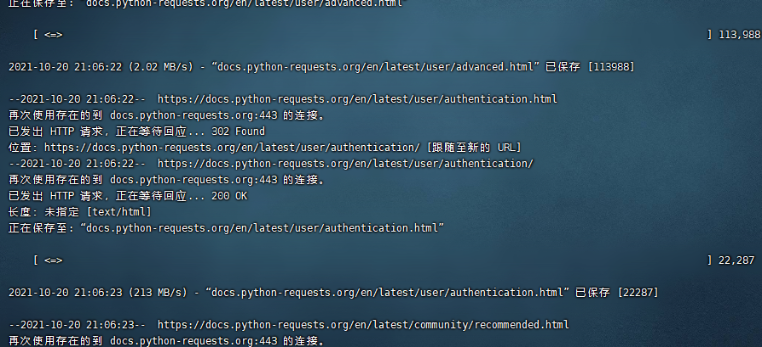
镜像下载整个网站并保存到本地
wget -c --mirror -U "Mozilla" -p --convert-links http://docs.python-requests.org
如图:
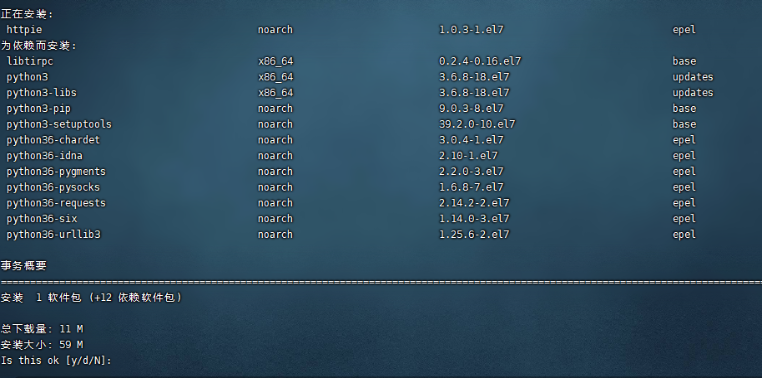
5、我们再来学习一下httpie的使用,这个工具也与curl类似不过比它好用,首先来看一下安装:
yum install httpie 或者apt install httpie、pip install httpie
如图:
6、http http://httpbin.org/get 我们使用它的命令试试,如图:
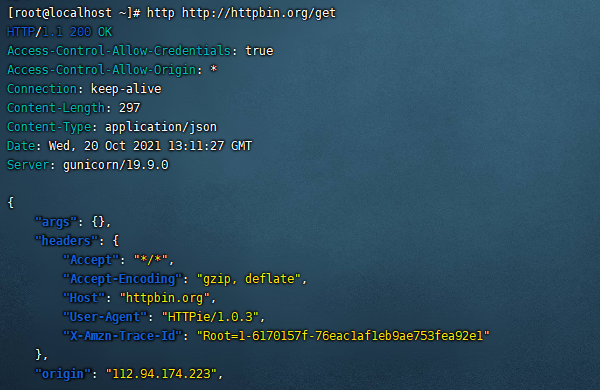
这样看起来是不是比curl更加的好用。
7、之前我们不是有镜像过一个网站到本地嘛?我们可以使用python内置的一个web服务器创建一个服务,因为在一般的linux上都预安装了python3的解释器。命令如下:
python3 -m http.server 如图:

然后我们访问我们的虚拟机地址http://192.168.150.139:8000/,然后网站就弄完了,是不是很简单(注意在访问的时候systemctl stop firewalld.service关闭防火墙,不然访问不了)
如图: