1、官方文档:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/readwrite-splitting/
2、链接上一篇文章:ShardingSphere学习之操作公共表
3、安装mysql:mysql学习之mysql安装与简介
4、可以参考之前的文章:mysql学习之主从复制
因为之前的文章有点问题,现在我们重新配置:
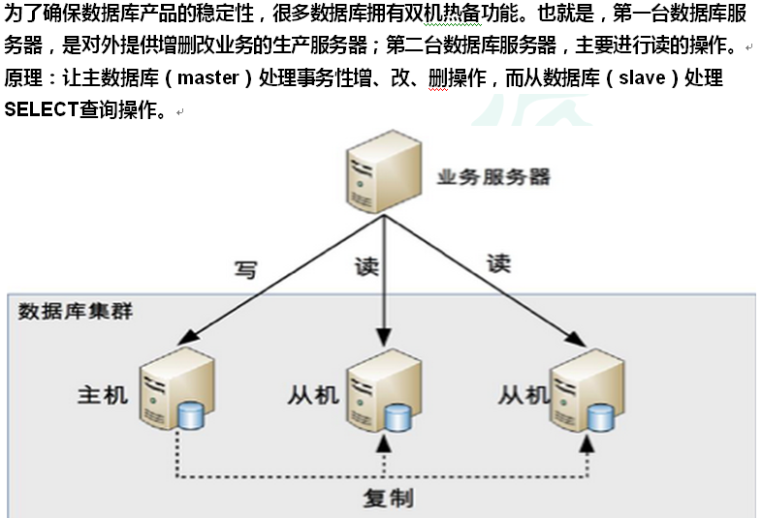
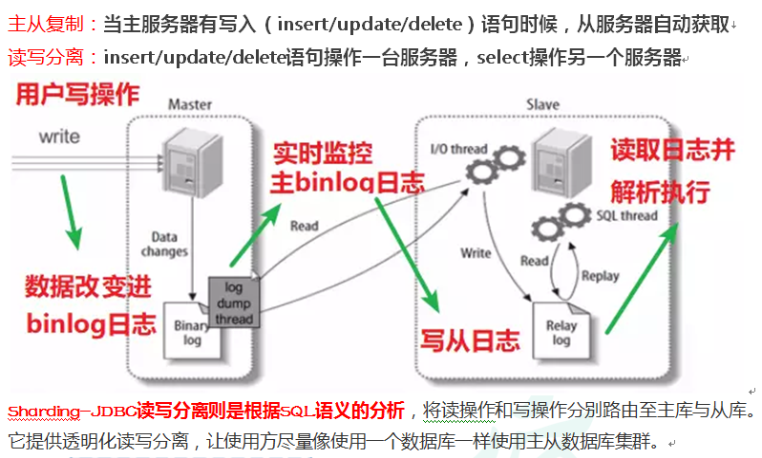
5、安装两个数据库(主写从读):
一个主数据库:192.168.152.141,下面简称141
一个从数据库:192.168.152.142,下面简称142
141,mysql配置:
[mysqld]
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
basedir = /opt/mysql/mysql-8.0.18
datadir = /opt/mysql/mysql-8.0.18/data
port = 3306
socket = /tmp/mysql.sock
character-set-server=utf8
log-error = /opt/mysql/mysql-8.0.18/data/mysqld.log
pid-file = /opt/mysql/mysql-8.0.18/data/mysqld.pid
#大小写敏感设置,不需要直接注释掉
lower_case_table_names = 1
#开启日志
log_bin = mysql‐bin
#设置服务id,主从不能一致
server_id = 1
#设置需要同步的数据库
binlog_do_db=user_db
#屏蔽系统库同步
binlog_ignore_db=mysql
binlog_ignore_db=information_schema
binlog_ignore_db=performance_schema
142,mysql配置:
[mysqld]
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
basedir = /opt/mysql/mysql-8.0.18
datadir = /opt/mysql/mysql-8.0.18/data
port = 3306
socket = /tmp/mysql.sock
character-set-server=utf8
log-error = /opt/mysql/mysql-8.0.18/data/mysqld.log
pid-file = /opt/mysql/mysql-8.0.18/data/mysqld.pid
#大小写敏感设置,不需要直接注释掉
lower_case_table_names = 1
# 开启日志
log_bin = mysql-bin
#设置服务id,主从不能一致
server_id = 2
#设置需要同步的数据库
replicate_wild_do_table=user_db.%
#屏蔽系统库同步
replicate_wild_ignore_table=mysql.%
replicate_wild_ignore_table=information_schema.%
replicate_wild_ignore_table=performance_schema.%
配置结束后重启两个mysql:service mysql restart
注意在mysql通过虚拟机复制后需将mysql目录中下data的auto.cnf文件删除后在重启,不然server_id重复会有问题
使用mysql客户端工具链接数据库
6、在141中参考配置(可不配置)
create user 'db_sync'@'192.168.152.141' identified by 'db_sync';
GRANT ALL PRIVILEGES ON *.* TO 'db_sync'@'192.168.152.141' WITH GRANT OPTION;
FLUSH PRIVILEGES;
# 这个配置在mysql8中有问题,用上面那两个配置脚本进行配置
GRANT REPLICATION SLAVE ON *.* TO 'db_sync'@'192.168.152.141' IDENTIFIED BY 'db_sync';
SELECT host,user from user;在141库中执行 :show master status
如图:

我们就能看到之前配置的内容。
7、在142中的配置
首先我们使用:show slave status 可以查看从数据库的相关状态
stop slave 先停止同步
使用下面的sql语句进行配置
CHANGE MASTER TO
master_host = '192.168.152.141',
master_user = 'root',
master_password = '123456',
master_log_file = 'mysql‐bin.000004',
master_log_pos = 2588;上面的配置就是刚刚在master中查到的相关的内容
配置完以后在
start slave 开始同步
show slave status 查看状态:


然后在主库中就添加删除修改数据从库就能够自动同步了
#查看从库状态Slave_IO_Runing和Slave_SQL_Runing都为Yes说明同步成功,如果不为Yes,请检查
error_log,然后
排查相关异常。
#注意 如果之前此从库已有主库指向 需要先执行以下命令清空
STOP SLAVE IO_THREAD FOR CHANNEL '';
reset slave all;
8、然后我们在使用sharding-jdbc进行配置读写分离
yarm配置:
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
# 配置数据源,给数据源起名称,多个数据源时使用逗号分隔
names: m1,m2,m0,m3
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.141:3306/course_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.142:3306/course_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
m0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.141:3306/user_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
m3:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.142:3306/user_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
#默认数据源,未分片的表默认执行库
sharding:
default-data-source-name: m1
rules:
readwrite_splitting:
dataSources:
ms:
staticStrategy:
writeDataSourceName: m0
readDataSourceNames: m3
loadBalancerName: random
loadBalancers:
random:
type: RANDOM
sharding:
# 分片算法配置
shardingAlgorithms:
# 这里对应shardingAlgorithmName: table-inline
table-inline:
type: INLINE
props:
sharding-count: 10
# cid为奇数时将数据存到course_2这张表中,当cid为偶数时,将数据存到course_1这种表中
algorithm-expression: course_$->{cid % 2 + 1}
# 这里对应shardingAlgorithmName: table-inline
db-inline:
type: INLINE
props:
sharding-count: 10
# user_id为奇数时将数据存到m2这张表中,当user_id为偶数时,将数据存到m1这种表中
algorithm-expression: m$->{user_id % 2 + 1}
# 这里对应shardingAlgorithmName: table-inline
user-inline:
type: INLINE
props:
algorithm-expression: t_user
# 分布式序列算法配置
keyGenerators:
# 这里对应keyGeneratorName: snowflake
snowflake:
type: SNOWFLAKE
# 分片审计算法配置
auditors:
# 这里对应 auditorNames:
# - sharding_key_required_auditor
sharding_key_required_auditor:
type: DML_SHARDING_CONDITIONS
tables:
# 表名
course:
# 库配置
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: db-inline
# 数据表配置
actualDataNodes: m$->{1..2}.course_$->{1..2}
tableStrategy:
standard:
shardingColumn: cid
shardingAlgorithmName: table-inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
# t_user:
# # 数据表配置
# actualDataNodes: m0.t_user
# tableStrategy:
# standard:
# shardingColumn: user_id
# shardingAlgorithmName: user-inline
# keyGenerateStrategy:
# column: user_id
# keyGeneratorName: snowflake
t_udict:
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
# 公共表
broadcastTables:
- t_udict
# 打开sql输出日志
props:
sql-show: true
logging:
config: classpath:logback-spring.xml
level:
org:
springframework:
boot:
autoconfigure:
logging: INFO
server:
port: 8082
mybatis-plus:
mapper-locations: classpath:xml/*.xml
# configuration:
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
测试:
插入一条数据
@Test
public void addUserDb() {
User user = new User();
user.setUsername("test2");
user.setUstatus("normal");
userMapper.insert(user);
}对应的库如下:

从图中我们数据插入的库是m0库,也就是主库
我们在来查询一条数据:
@Test
public void findUserDb() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
//设置 userid 值
wrapper.eq("user_id",1609375562340507650L);
User user = userMapper.selectOne(wrapper);
System.out.println(user);
}对应的库如下:

从图中我们数据查询的库是m3库,也就是从库
我们在来删除一条数据:
@Test
public void deleteUserDb() {
userMapper.deleteById(1609375562340507650L);
}对应的库如下:

从图中我们可以看到的库是m0库,也就是主库
我们在来修改一条数据:
@Test
public void updateUserDb() {
User user = new User();
user.setUserId(1609762516236238849L);
user.setUsername("update");
userMapper.updateById(user);
}对应的库如下:

从图中我们可以看到的库是m0库,也就是主库
从这几个测试中,我们能够看到数据的增删改 操作的是m0的库,也就是主库,查询操作的库是m3的库,也就是从库。