1、官方文档:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding/
2、链接上一篇文章:ShardingSphere学习之分页
3、创建两个数据库,怎么创建可以参考:mysql学习之mysql安装与简介
两个库分别为:141和142
4、现在我们在约定一下数据储存的规则:
数据库规则:(1 ) userid为偶数数据添加141数据库
为奇数数据添加142数据库
表规则:( 1 ) cid为偶数数据添加course_1表
为奇数数据添加course_2表
5、其他代码与上一篇文章基本相同,就是配置修改了一下,配置如下:
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
# 配置数据源,给数据源起名称,多个数据源时使用逗号分隔
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.141:3306/course_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.152.142:3306/course_db?useUnicode=true&characterEncoding=utf8
username: root
password: 123456
#默认数据源,未分片的表默认执行库
sharding:
default-data-source-name: m1
rules:
sharding:
# 分片算法配置
shardingAlgorithms:
# 这里对应shardingAlgorithmName: table-inline
table-inline:
type: INLINE
props:
sharding-count: 10
# cid为奇数时将数据存到course_2这张表中,当cid为偶数时,将数据存到course_1这种表中
algorithm-expression: course_$->{cid % 2 + 1}
# 这里对应shardingAlgorithmName: table-inline
db-inline:
type: INLINE
props:
sharding-count: 10
# user_id为奇数时将数据存到m2这张表中,当user_id为偶数时,将数据存到m1这种表中
algorithm-expression: m$->{user_id % 2 + 1}
# 分布式序列算法配置
keyGenerators:
# 这里对应keyGeneratorName: snowflake
snowflake:
type: SNOWFLAKE
# 分片审计算法配置
auditors:
# 这里对应 auditorNames:
# - sharding_key_required_auditor
sharding_key_required_auditor:
type: DML_SHARDING_CONDITIONS
tables:
# 表名
course:
# 库配置
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: db-inline
# 数据表配置
actualDataNodes: m$->{1..2}.course_$->{1..2}
tableStrategy:
standard:
shardingColumn: cid
shardingAlgorithmName: table-inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
# 打开sql输出日志
props:
sql-show: true
logging:
config: classpath:logback-spring.xml
level:
org:
springframework:
boot:
autoconfigure:
logging: INFO
server:
port: 8082
mybatis-plus:
mapper-locations: classpath:xml/*.xml
# configuration:
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
6、测试:
1)首先我们来插入一条数据
@Test
public void addCourseDb() {
Course course = new Course();
course.setCname("test");
course.setUserId(111L);
course.setCstatus("normal");
courseMapper.insert(course);
}根据上面的代码逻辑,user_id为奇数,那么这条数据应该插入到m2的数据库中(142)
如果根据雪花算法生成的id为偶数,那么就会将数据插入到course1中,奇数插入到course2中
执行如图:

从图中我们知道cid生成的id为偶数,那么到底插入到了哪个数据中了呢?
如图:
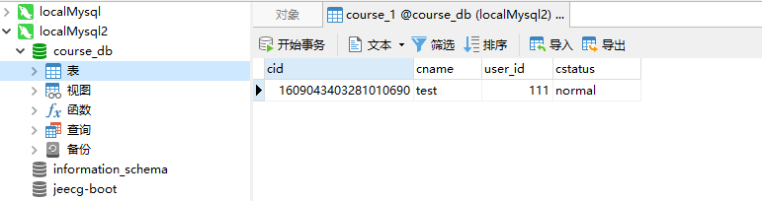
从图中我们能够看到,数据已经正常的插入到了相关的库中。
2)批量插入数据
@Test
public void addCourse() {
List<Course> list = new ArrayList<>();
for(int i=1;i<=10;i++) {
Course course = new Course();
course.setCname("java"+i);
course.setUserId(100L+i);
course.setCstatus("Normal"+i);
list.add(course);
}
courseService.saveBatch(list);
}执行的结果如下:
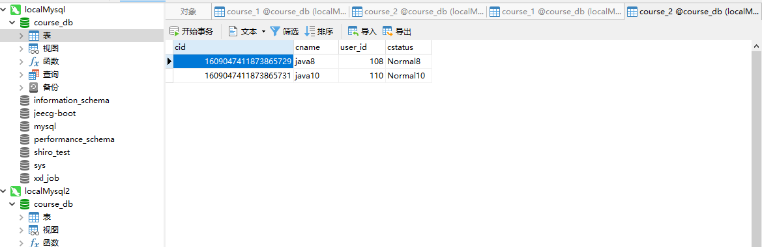
图中我们能够看到,数据也能够正常的插入到数据库中了
3)分页查询
@Test
public void pageCourse() {
Page<Course> page = courseService.page(new Page<>(1, 100), Wrappers.<Course>lambdaQuery()
.orderByAsc(Course::getCid)
);
System.out.println(page.getRecords());
}经测试也是没有问题的。
到现在我们的水平分库分表就已经能够自己搭建了,是不是有感觉到成长了。