要爬取的网站:https://m.sj.enterdesk.com/
这个壁纸网站的壁纸其实之前我也有爬过,那是在我第一份工作的时候,现在想想时间过得真快,往事如烟不堪回首。。。。。。
说正事,我用之前的爬取的方法再次爬取这个网站时发现爬不到数据,仔细一看原来它做了一些相关的反爬虫的机制,这我就来兴趣了,下面开始说爬取过程。
1、爬取的框架使用的是java webmagic框架。(很多内容就不想在细说了,有时间在写一篇关于webmagic相关用法的文章)
2、使用maven创建项目,导入编写pom.xml文件,完整的pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>xyz.haijin.spider</groupId>
<artifactId>WallpaperSpider</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.6-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.6-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>
</project>3、使用webmagic 0.7.6-SNAPSHOT时,中央仓库好像还没发布,怎么办?
打开GitHub:https://github.com/code4craft/webmagic
将代码拷贝到你的本地:https://github.com/code4craft/webmagic.git
然后将项目中的
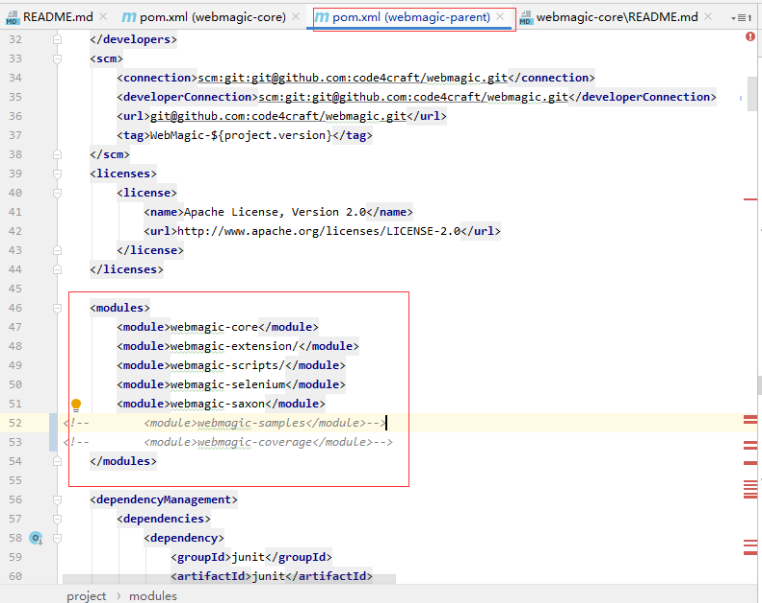
webmagic-parent、webmagic-core、webmagic-extension install打包到你的本地maven仓库中,注意
<!-- <module>webmagic-samples</module>-->
<!-- <module>webmagic-coverage</module>-->
这两个模块先将其注释掉,不然会导致打包不了,其中有几个插件下载不下来
如图:
4、编写logback日志配置文件logback.xml,如下:
<?xml version="1.0" encoding="UTF-8"?>
<!-- scan:当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。
默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="60 seconds" debug="true">
<property name="CONSOLE_LOG_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} |-[%-5p] in %logger.%M[line-%L] -%m%n"/>
<property name="log.path" value="D:/log" />
<!-- 输出到控制台 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!-- Threshold=即最低日志级别,此appender输出大于等于对应级别的日志
(当然还要满足root中定义的最低级别)
-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>trace</level>
</filter>
<encoder>
<!-- 日志格式(引用变量) -->
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 追加到文件中 -->
<appender name="file" class="ch.qos.logback.core.FileAppender">
<file>${log.path}/hello.log</file>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<appender name="file2" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${log.path}/world.log</file>
<!--日志文件输出格式-->
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>UTF-8</charset> <!-- 设置字符集 -->
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录
文件超过最大尺寸后,会新建文件,然后新的日志文件中继续写入
如果日期变更,也会新建文件,然后在新的日志文件中写入当天日志
-->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 新建文件后,原日志改名为如下 %i=文件序号,从0开始 -->
<fileNamePattern>${log.path}/world-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!-- 每个日志文件的最大体量 -->
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>1kb</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 日志文件保留天数,1=则只保留昨天的归档日志文件 ,不设置则保留所有日志-->
<maxHistory>1</maxHistory>
</rollingPolicy>
</appender>
<root level="trace">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="file"/>
<appender-ref ref="file2"/>
</root>
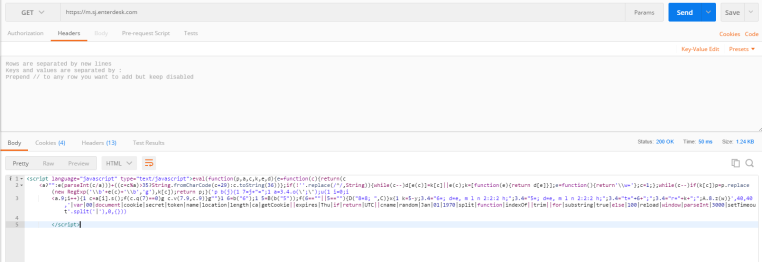
</configuration>5、然后我们再来看一下https://m.sj.enterdesk.com/
这个网站的爬取过程,我们直接请求这个url时,它返回并不是html的源码,而是返回了一段js的代码,我们将这段js代码放到txt文本文件中,在用将其后缀修改为html用浏览器打开后,会发现页面每隔一小段时间就会刷新一下,
这时我们明白,存在其他的一些值,如cookie能够让它返回正确的html源码。
postman中返回的值:
这是我们打开浏览器,查看相关的cookie值,如图:
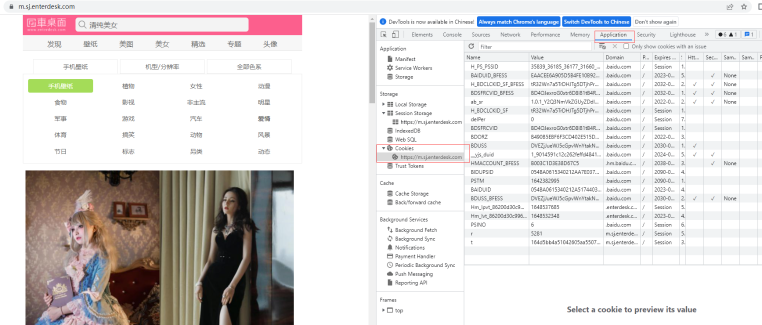
我们发现这里有一大堆的值,我们不知道具体是哪一个,但没关系我们可以将它所有的值都作为请求的cookie参数,然后排除一些没用的值,最后得到的值为:
.setDomain("m.sj.enterdesk.com")
.addCookie("r", "5281")
.addCookie("t", "164d5bb4a51042605aa5507a6f65af27");
返回结果如下:

6、我们已经能够正确返回它的源代码了,现在我们需要先爬取它的壁纸类型,保存在数据库中,爬取壁纸的时候能够方便分类。
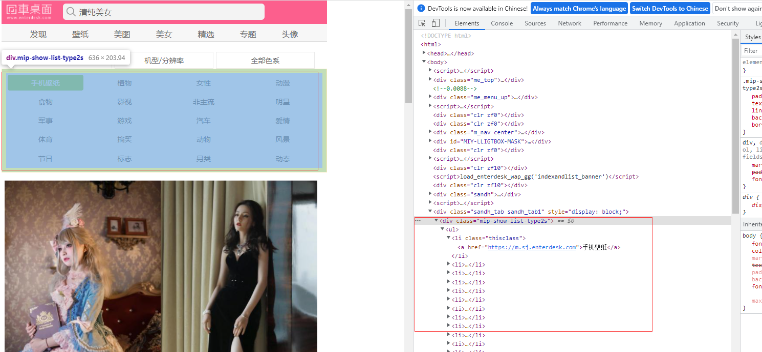
右键copy 选择copy full xpath
然后在代码中添加相关的xpath,再次请求,返回的结果如下:
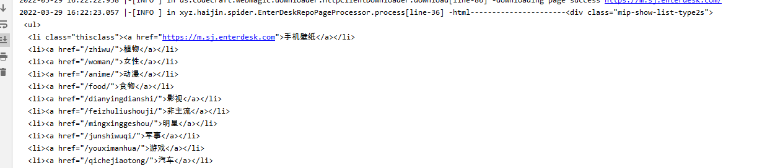
这样我们就完成了爬虫的第一步,也是最重要的一步。
7、当前项目完整的截图:
8、相关代码:
package xyz.haijin.spider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @Author liuhaijin
* @Date 2022/3/29
*/
public class EnterDeskRepoPageProcessor implements PageProcessor {
/**
* 日志对象
*/
private Logger logger = LoggerFactory.getLogger(EnterDeskRepoPageProcessor.class);
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(10000)
//添加cookie之前一定要先设置主机地址,否则cookie信息不生效
.setDomain("m.sj.enterdesk.com")
//添加抓包获取的cookie信息
.addCookie("r", "5281")
.addCookie("t", "164d5bb4a51042605aa5507a6f65af27");
//添加请求头,有些网站会根据请求头判断该请求是由浏览器发起还是由爬虫发起的
// .addHeader("User-Agent",
// "ozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.516.400 QQBrowser/9.4.8188.400")
// .addHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
// .addHeader("Accept-Encoding", "gzip, deflate, sdch").addHeader("Accept-Language", "zh-CN,zh;q=0.8")
// .addHeader("Connection", "keep-alive").addHeader("Referer", "https://m.sj.enterdesk.com/");
@Override
public void process(Page page) {
logger.info("html----------------------"+page.getHtml()
.xpath("/html/body/div[11]/div").toString()
);
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new EnterDeskRepoPageProcessor()).addUrl("https://m.sj.enterdesk.com/").thread(5).run();
}
}
9、解析html可以使用xpath来进行解析,相关请参考:
10、gitee地址:
https://gitee.com/liu-haijin/wallpaper-spider