在风控模型中,SMOTE过采样方法的主要作用是通过合成少数类样本来增加其在数据集中的数量,以达到样本平衡。这对于改善模型的训练效果至关重要。通过SMOTE过采样,可以使得模型更好地学习到少数类别的特征,从而提高模型的泛化能力和准确性。此外,SMOTE过采样方法还可以减少模型的过拟合倾向,提高模型的稳健性(Robustness)。
1.对于每一个少数类样本,计算其与所有其他少数类样本之间的距离,并找到其K个最近邻居。
2.从这K个最近邻居中随机选择一个样本,并计算该样本与当前样本的差异。
3.根据差异比例,生成一个新的合成样本,该样本位于两个样本之间的连线上。
4.重复上述步骤,生成指定数量的合成样本。
SMOTE算法的关键是通过插值生成合成样本,从而使得少数类样本的特征空间得到扩展。这有助于模型更好地探索和学习少数类的特征,提高模型的性能。
除了SMOTE,还有其他一些常用的过采样方法,如随机过采样(Random Over-sampling)、自适应综合过采样(ADASYN,Adaptive Synthetic Sampling)等。
原理:简单复制少数类样本来平衡数据集。
优点:简单易实施,适用于小型数据集。
缺点:
-容易导致过拟合问题,复制的样本可能会引入噪声。
-对于较大的数据集,会导致内存占用过高。
原理:根据样本密度分布来调整合成样本的数量。
优点:能够更好地处理样本密度不均衡的情况,适用于非线性问题。
缺点:计算成本较高,对于高维数据集效果可能不佳。
相比之下,SMOTE具有以下优点:
-在处理数据不平衡问题时表现良好,能够有效增加少数类样本。
-基于合成样本的插值方法能够在特征空间中扩展少数类样本,有助于模型学习到更多的特征信息。
-实现简单,易于理解和应用。
当然,SMOTE方法也有一些潜在的缺点,包括:
-对于噪声和离群点敏感
-无法处理样本重叠问题
-可能导致模型过拟合
-处理多类别不平衡问题的能力有限
下面是一个简单的Python代码示例,展示如何使用imbalanced-learn库中的SMOTE来进行过采样:
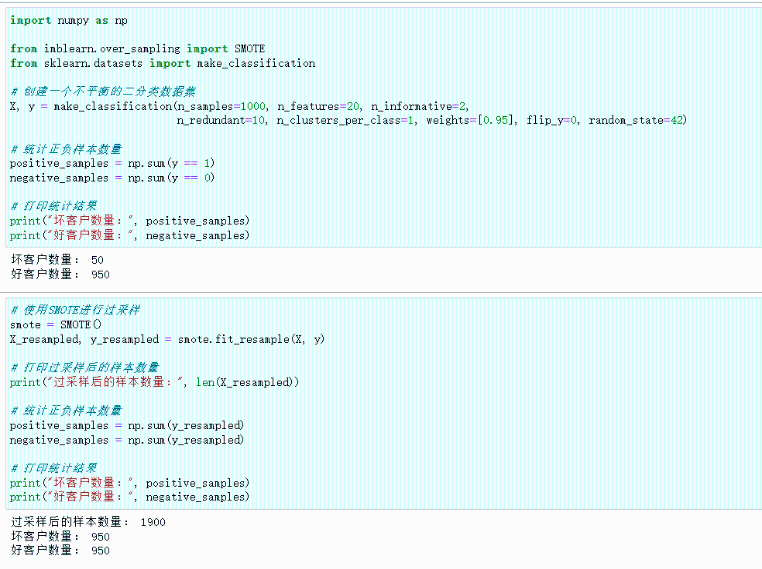
可以看到最初样本中坏客户只占5%,而经过SMOTE过采样之后好坏样本比例达到了1:1
SMOTE过采样方法在风控模型中发挥着重要作用,通过生成合成样本来平衡数据集,从而提高模型的准确性和鲁棒性。相比其他过采样方法,SMOTE在处理数据不平衡问题上具有一定的优势,且易于实现和理解。当然,在应用过程中需要结合实际情况,根据数据集的特点和需求来决定使用哪种过采样方法。