1、资料准备
pom文件:
<!--itextPdf 依赖start-->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13.3</version>
</dependency>
<dependency>
<groupId>org.bouncycastle</groupId>
<artifactId>bcpkix-jdk15on</artifactId>
<version>1.70</version>
</dependency>
<dependency>
<groupId>org.bouncycastle</groupId>
<artifactId>bcprov-jdk15on</artifactId>
<version>1.70</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
<!--itextPdf 依赖end-->
资料准备:
资料地址
链接:https://pan.baidu.com/s/12wRos_422Y6ULySthAw63Q
提取码:3dyb
描述:源文件 = 源文件pdf
Demo3.pdf = 第一次签章
Demo4.pdf = 第二次签章(在第一次签章的基础上再签一次)
Tomcatocc.p12 通过jdk生成的p12证书
Demo3.asn = demo3.pdf /contents字典后面的二进制流的解码文件 (有注释,对应itext5源码)
Demo4.asn = demo4.pdf /contents 字典后面的二进制流的解码文件
ASN1.zip = ASN文件解码工具
2、pdf签章原理
通过文本编辑器(vscode)直接打开demo3.pdf直接查看流数据,会发现带有/sig

字典的数据 往右边看还有可以看到 /contents字典后面跟着一串流数据。那就是签章完之后的信息。国际规范为pkcs7结构体(demo3.asn)。实际上p7结构体是通过特定的asn.1结构组织而成,打个比方json = asn.1,接口报文 = p7结构体。这是两者的关系。
当然,对应的印章图片流就在/sig上面

其实p12证书也是由asn.1组成。
每次签章的时候,都会在pdf数据末尾添加一串签章信息,都是由/sig /contents等字典组成。/contents前面还有一个/bytesRange的字典,这个字典记录了签章的数据范围以及摘要的范围。使得每次签章的验签都是独立的(具体的话需要百度一下/byteRange字典的知识,我没完全理解)。
3、itext5签章流程
通过用户指定的摘要算法:
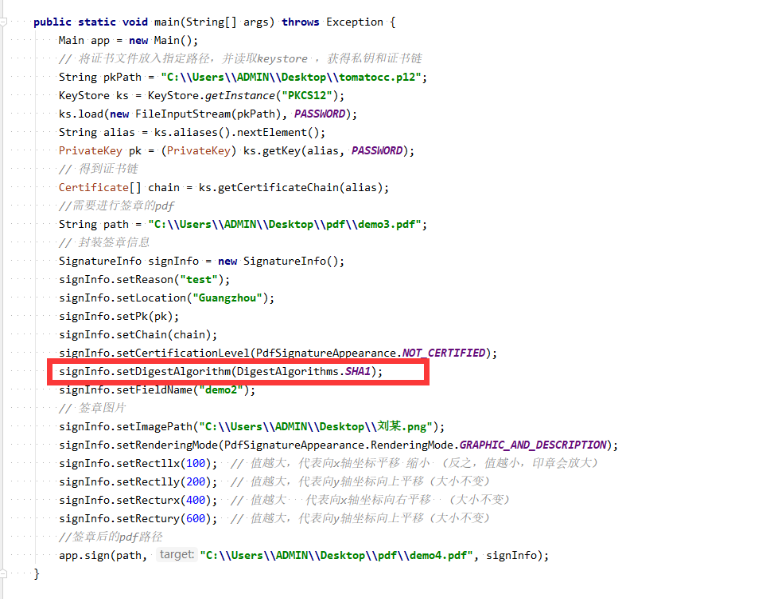
对pdf全文进行一次hash摘要。当然在执行这个摘要方法前需要调用一下preClose()方法。
下面是itext5 MakeSignature.java的源码
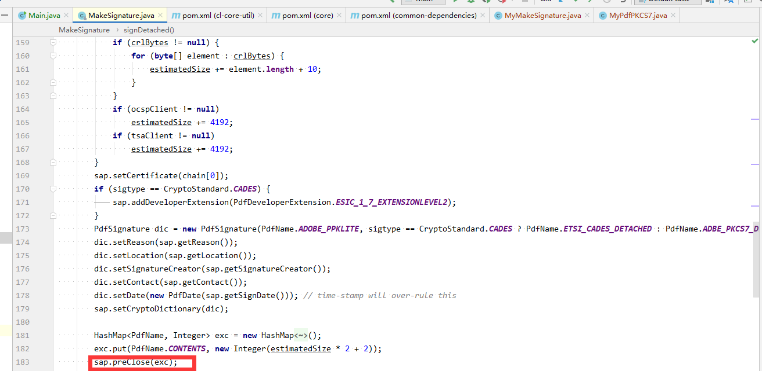
这个方法用来开辟/contents的预留空间(用来存放p7结构) 并生成/byteRange字典的范围。
紧接着就是加密摘要:
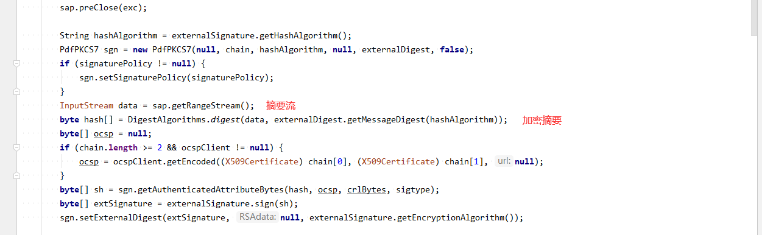
可以尝试把摘要流输出到控制台(需要拿到源码然后修改),你会发现上面的preClose方法做了些什么(就是上文所说)
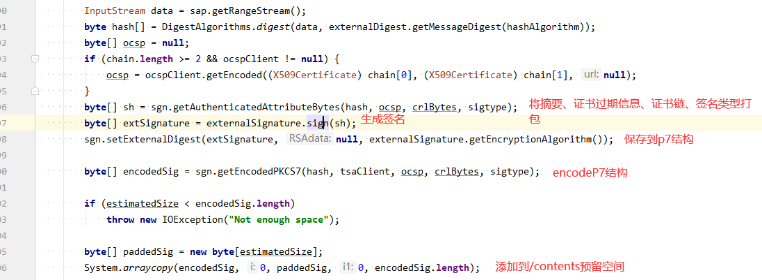
4、验签
延签其实就是解析pdf文件里面的字典。关键的/sig、/byteRange、/contents。获取到/contents的数据流,反解析成asn.1的结构生成p7 一步步进行判断。(具体的看itext5源码)
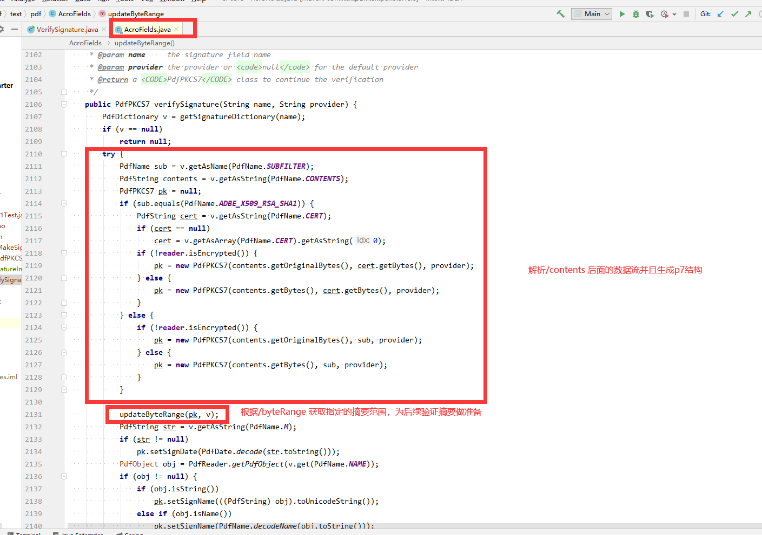

验签描述的比较简单,实际详细理解需要进源码打断点
5、总结
Pdf签章流程大体分为:1、根据证书等信息生成预留的/contents的空间,确定好/byteRange的范围,对pdf原文进行hash摘要。通过pdf摘要、证书、等信息生成签名。一并保存到p7。然后再将p7保存到/contents的预留空间中。而验签就是泛解析/contents的数据流,生成p7,对原文再做一次hash摘要对比p7里面的
摘要判断是否被串改。以及签名的验证。多次签章的时候,摘要范围的判断是根据/byteRange的数据范围获取当前签章所属的摘要范围。P7里面存着许多信息,比如摘要算法的oid,签名算法的oid。都是用来为后续验签做好准备。里面还有各种的证书链(一般是根证书),和时间戳等信息,具体的看demo3.asn。以上是基于国际规范的pdf签章。而国密的签章由于技术壁垒问题,无法深入了解。单单是sm2证书的解析就能卡死我